OpenClaw 多 Agent 配置实战:别让 LLM 做编排
手把手配置 OpenClaw 多 Agent 系统。8 级 binding 优先级详解、Lobster 确定性流水线 vs sessions_send 对比、飞书集成、成本控制策略,附可复制的 3 Agent 起步配置。
OpenClawMulti-AgentAI ArchitectureLobsterAgent Orchestration
1621 字
2026-04-02

你的 OpenClaw 多 Agent 系统最大的敌人,不是配置写错了,是让 LLM 做编排。
我见过太多人的多 Agent 配置是这样的:一个 Supervisor Agent 接收所有消息,用 sessions_send 调用各个专家 Agent,专家做完回传,Supervisor 汇总。看起来很优雅,对吧?但实际跑起来,Supervisor 每次路由决策都是一次完整的 API 调用,专家回传又是一次,一个简单的"帮我写篇文章"可能触发 6-8 次 API 请求。更糟的是,如果防递归规则没配好,Agent 之间循环委派,Cogent 的报告记录过有团队几分钟内烧掉数千美元。
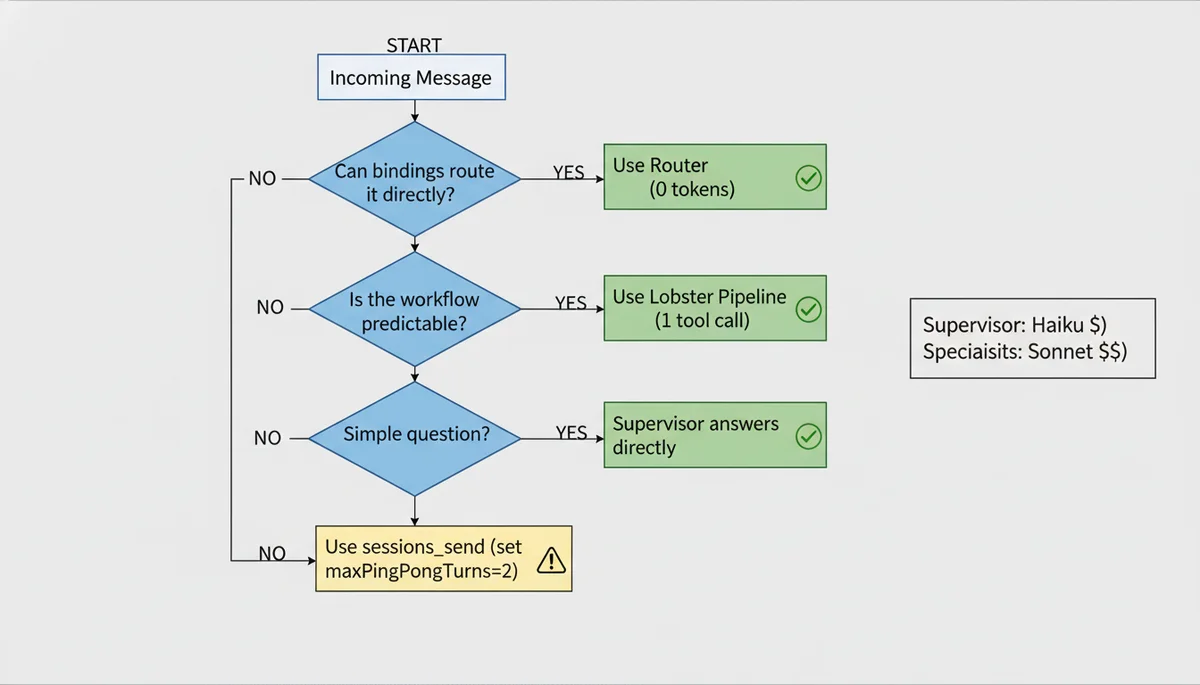
正确的起步姿势是:bindings 做静态路由 + Lobster 做确定性流水线,只在真正需要 LLM 动态判断时才用 sessions_send。这篇文章手把手带你完成整套配置。
如果你还没装过 OpenClaw,先看 OpenClaw 安装配置指南。
为什么要多 Agent:单 Agent 的三个天花板
一个 Agent 跑了两周以上,三个问题一定会冒出来——不是模型变笨了,是架构扛不住。
第一个天花板是记忆污染。 Agent 在回答问题时,会从所有领域的记忆中检索上下文。你问博客草稿的事,它把上周的 debug 笔记也搜出来了。记忆索引膨胀到 200MB 以上时,响应速度也会明显变慢。这不是搜索算法的问题,是一个向量库里塞了太多不相关的领域知识,检索精度必然下降。
第二个天花板是人设冲突。 一个 SOUL.md 里同时写「严谨的技术写手」和「随意的朋友聊天风格」,两种人格必然互相泄漏。你在工作群里收到一条带emoji的随意回复,或者在朋友群里收到一段公文体——这就是人设冲突的典型症状。OpenClaw 的 DM 安全模式文档也提到:没有隔离的情况下,多个用户共享同一个会话上下文会导致私密信息泄漏。
第三个天花板是模型不匹配。 写代码需要 Claude Sonnet,头脑风暴用 GLM-4.7 效果更好,路由决策用 Haiku 就够了。一个 Agent 只能配一个模型,意味着你要么为简单任务多花钱,要么为复杂任务用了能力不够的模型。研究显示,混合模型架构比统一用顶级模型降低 40-60% 成本,同时不牺牲质量。
多 Agent 架构把这三个问题一次解决:每个 Agent 独立的工作区、记忆、人设、模型配置。底层原理参考 OpenClaw 架构深度解析。
核心概念:一个 Agent 由什么组成
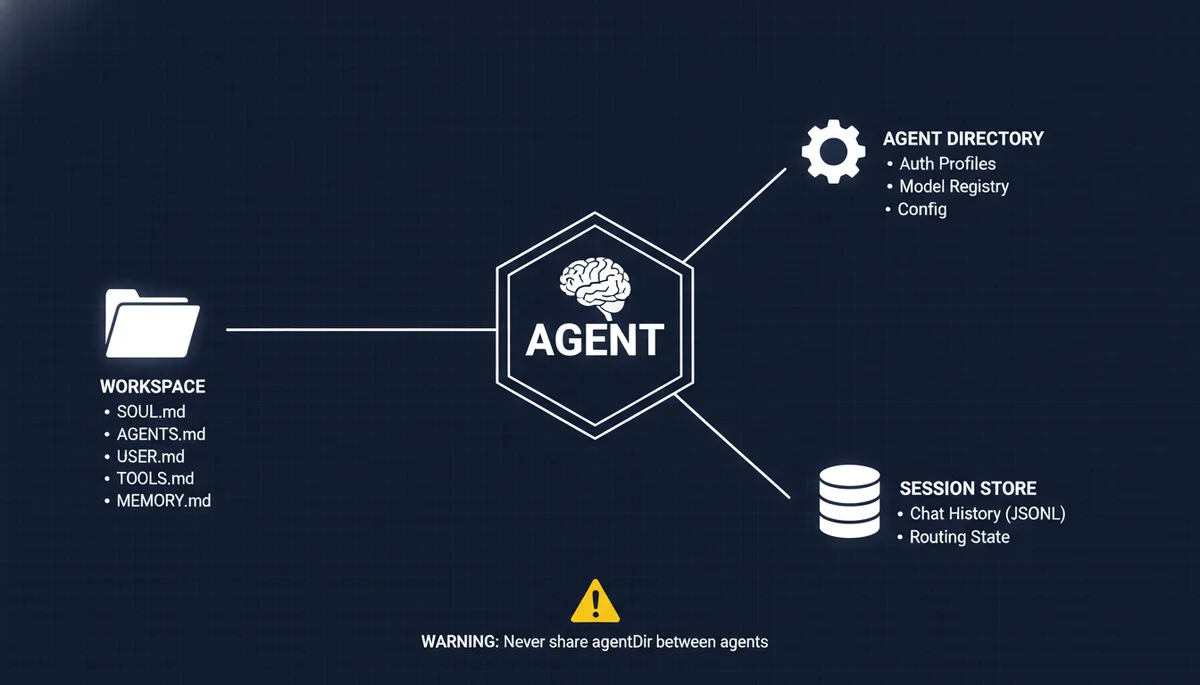
在 OpenClaw 里,每个 Agent 是三样东西的组合,缺一不可:
| 组件 | 路径 | 作用 |
|---|---|---|
| 工作区 | ~/openclaw-agents/<名称>/ | SOUL.md、AGENTS.md、USER.md、TOOLS.md、MEMORY.md |
| Agent 目录 | ~/.openclaw/agents/<agentId>/ | 认证配置、模型注册、Agent 专属设置 |
| 会话存储 | ~/.openclaw/agents/<agentId>/sessions/ | 聊天记录(JSONL 格式)、路由状态 |
铁律:永远不要让两个 Agent 共享 Agent 目录。 共享会导致认证冲突、会话串台、记忆交叉污染。我在 自动化避坑指南 里详细分析过这个问题——一旦两个 Agent 的 session store 混在一起,你会看到 Agent A 突然用 Agent B 的语气说话,debug 起来极其痛苦。
第一步:创建 Agent 工作区
用 CLI 创建 Agent
# 创建协调者 Agent(团队管理者)
openclaw agents add supervisor
# 创建专家 Agent
openclaw agents add writer
openclaw agents add coder
openclaw agents add researcher
每条命令自动生成一个完整的工作区目录:
~/openclaw-agents/writer/
├── AGENTS.md # Agent 能力和规则
├── SOUL.md # 人设、语气、价值观
├── USER.md # 用户偏好和上下文
├── TOOLS.md # 可用工具和限制
├── MEMORY.md # 持久记忆笔记
├── HEARTBEAT.md # 主动巡检规则
└── IDENTITY.md # 名称、头像、元数据
命名规则:只允许小写字母、数字和连字符(a-z、0-9、-),必须以字母开头,不能以连字符结尾。比如 writer、code-reviewer、research-v2 都可以。
为每个 Agent 定制 SOUL.md
SOUL.md 是 Agent 的灵魂文件,决定了它的性格和行为边界。以下是一个写手 Agent 的实际配置:
# 写手 Agent
你是一名专注于 AI 工程领域的技术内容写作者。
## 规则
- 使用清晰直接的语言,不说废话
- 用具体案例代替抽象解释
- 每篇文章 1500-2500 字
- 适当加入代码片段
- 禁止生成占位内容——每个章节都必须有实质内容
## 语气
专业但不端着。像跟同事解释技术问题,不像写论文。
## 可用工具
- tavily-search(网络搜索)
- memory_search(回忆历史文章)
- read/write(文件读写)
## 禁用工具
- exec(不许执行命令)
- browser(不许操作浏览器)
关键细节:工具列表一定要写在 SOUL.md 里。OpenClaw 2026.3.2 之后默认关闭所有工具权限——这是 Reddit 上大量用户反馈 Agent"突然变笨"的根源。不是模型变了,是工具被关了。在 SOUL.md 和 openclaw.json 两个地方都要配工具白名单。
第二步:为每个 Agent 配不同模型
不同 Agent 用不同模型,这是多 Agent 最直接的成本优化手段。
# Supervisor:快速便宜,只做路由决策
openclaw agents config set supervisor model claude-3.5-haiku
# 写手:强推理,长文生成
openclaw agents config set writer model deepseek-r1
# 程序员:最强代码模型
openclaw agents config set coder model claude-sonnet-4
# 研究员:工具调用和信息综合能力强
openclaw agents config set researcher model gpt-4.1
模型选择策略
| Agent 类型 | 推荐模型 | 理由 |
|---|---|---|
| Supervisor | Claude Haiku / GPT-4.1-mini | 路由决策快、成本低,不需要深度推理 |
| 写手 | DeepSeek-R1 / Claude Sonnet | 长文生成和逻辑组织能力强 |
| 程序员 | Claude Sonnet / Codex | 代码质量和工具调用最好 |
| 研究员 | GPT-4.1 / Claude Sonnet | 综合分析和多工具协调能力强 |
| 创意 | GLM-4.7 / DeepSeek | 发散思维好,创意场景性价比高 |
核心洞察:Supervisor 是你最不应该花钱的 Agent。 它只做分发决策——“这条消息应该给谁处理?"——这个判断 Haiku 就能做得很好。把昂贵的 API 调用留给真正干活的专家 Agent。实际测算下来,Supervisor 用 Haiku + 专家用 Sonnet 的混合架构,比全部用 Sonnet 便宜 40-60%。
第三步:配置 Bindings——8 级优先级路由
Bindings 是 openclaw.json 中的确定性路由规则,决定哪条消息交给哪个 Agent。这是零 token 开销的路由方式——不需要 LLM 参与判断,纯规则匹配。
完整配置示例
{
agents: {
list: [
{
id: "supervisor",
workspace: "~/openclaw-agents/supervisor",
default: true
},
{
id: "writer",
workspace: "~/openclaw-agents/writer"
},
{
id: "coder",
workspace: "~/openclaw-agents/coder"
},
{
id: "researcher",
workspace: "~/openclaw-agents/researcher"
}
]
},
bindings: [
// 精确 peer 匹配(优先级最高)
{
agentId: "writer",
match: { channel: "telegram", peer: { kind: "group", id: "writing_group_id" } }
},
{
agentId: "coder",
match: { channel: "telegram", peer: { kind: "group", id: "coding_group_id" } }
},
// 飞书按 account 路由
{
agentId: "supervisor",
match: { channel: "feishu", accountId: "work-bot" }
},
{
agentId: "writer",
match: { channel: "feishu", accountId: "writing-bot" }
},
// 频道级默认(兜底)
{
agentId: "supervisor",
match: { channel: "telegram" }
}
]
}
8 级 Binding 优先级速查表
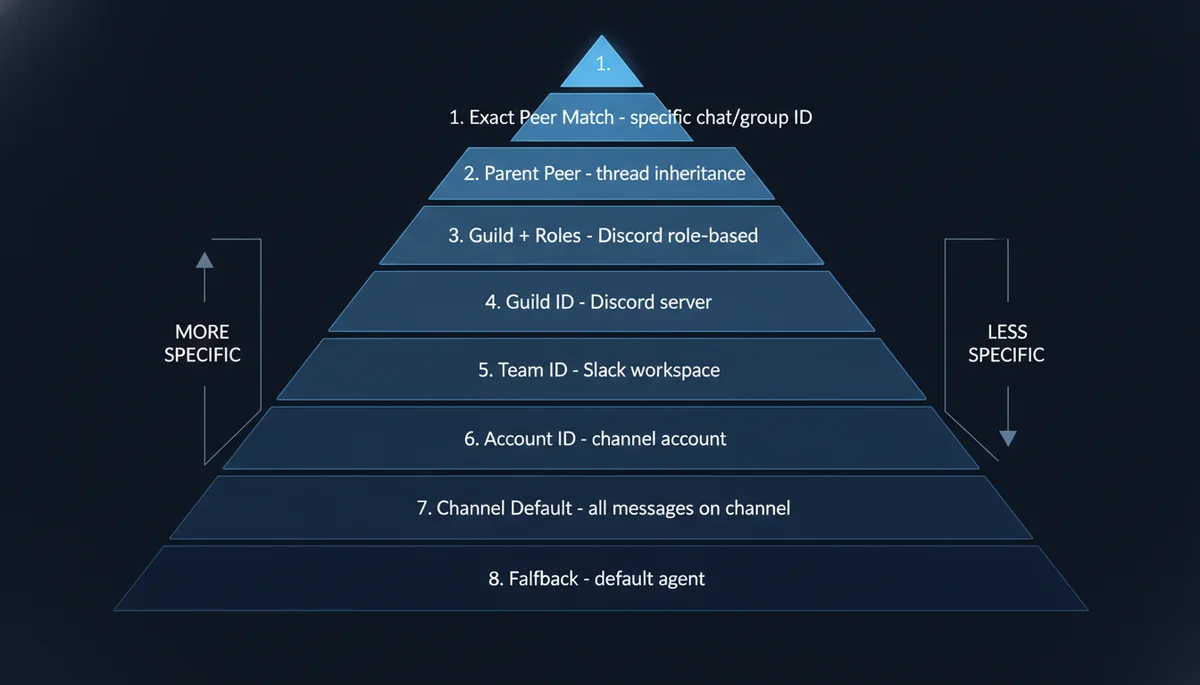
这是官方文档确认的完整优先级,从高到低:
| 优先级 | 匹配条件 | 典型用途 |
|---|---|---|
| 1 | 精确 peer(DM/群组 ID) | 特定群聊 → 特定 Agent |
| 2 | 父级 peer(话题继承) | 话题帖继承父群的路由 |
| 3 | Guild ID + 角色 | Discord 按角色路由 |
| 4 | Guild ID | Discord 服务器级 |
| 5 | Team ID | Slack 工作区级 |
| 6 | Account ID | 同频道不同账号 |
| 7 | Channel 级默认 | 该频道所有消息 |
| 8 | Fallback 兜底 | default: true 的 Agent |
关键细节:如果一条 binding 同时设了多个匹配字段(比如 peer + accountId),这些字段之间是 AND 关系——必须全部满足才匹配。同一优先级下,配置中靠前的规则胜出。
验证路由配置
配好之后一定要验证,不要盲目信任配置文件:
# 查看所有活跃的 bindings 和实际路由顺序
openclaw agents list --bindings
# 探测特定频道的路由情况
openclaw channels status --probe
第四步:Agent 间通信——先想清楚用哪种
这是整篇文章最重要的决策点。OpenClaw 提供两种 Agent 间协作方式,选错了代价很大。
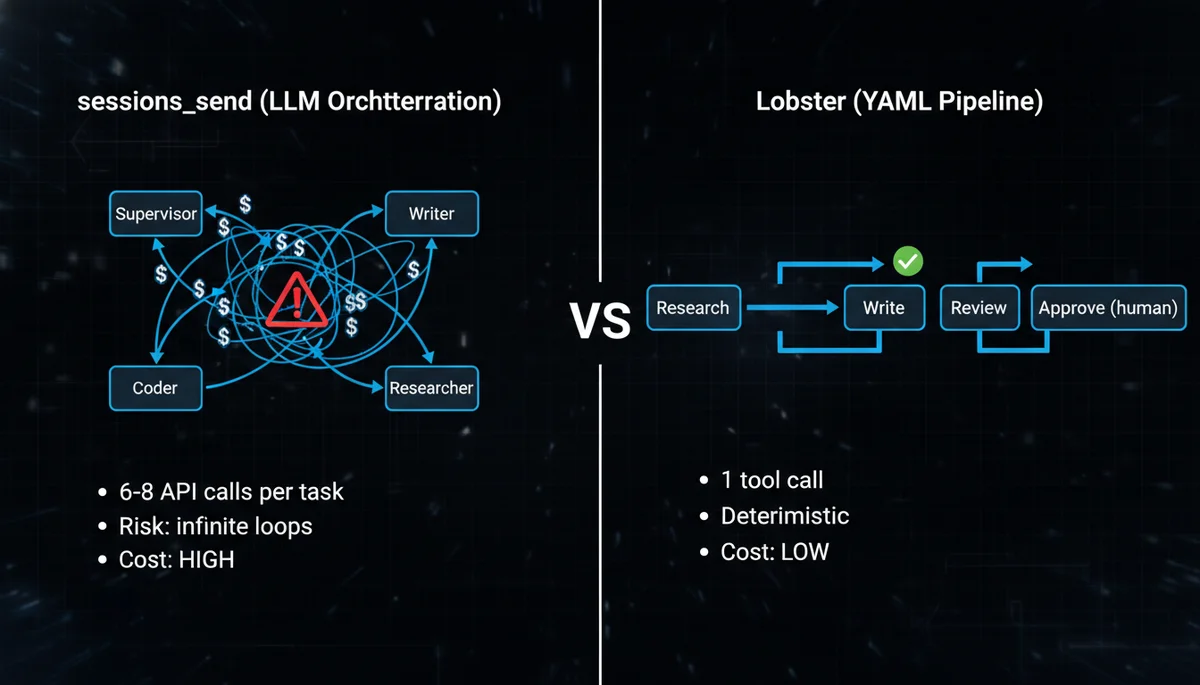
方案 A:Lobster 确定性流水线(推荐起步)
Lobster 是 OpenClaw 的原生工作流引擎。核心理念用一句话说清楚:LLM 负责创意工作(写文章、做调研),YAML 负责编排(谁先谁后、什么条件跳过、什么时候要人审批)。
为什么不让 LLM 做编排?一位开发者在 dev.to 分享了他的实战:尝试了 5 种方案后发现,把流程控制写在 prompt 里(“如果审核不通过就回到第 2 步,最多重试 3 次”),LLM 会数错次数、跳过步骤、甚至陷入无限循环。YAML 文件不会犯这种错误。
第一步:安装和启用 Lobster
# 安装 Lobster CLI(在 OpenClaw Gateway 所在的机器上)
pnpm install lobster
# 验证安装
lobster --help
lobster doctor
然后在 openclaw.json 中启用 Lobster 工具:
{
"tools": {
"alsoAllow": ["lobster"]
}
}
如果只想让特定 Agent 使用 Lobster(比如只给 Supervisor),可以在 Agent 级别启用:
{
"agents": {
"list": [
{
"id": "supervisor",
"tools": { "alsoAllow": ["lobster"] }
}
]
}
}
第二步:写一个 YAML 工作流文件
在你的工作区创建一个 .lobster 文件。以博客内容生产为例,创建 blog-pipeline.lobster:
name: blog-content-pipeline
args:
topic:
default: "OpenClaw security best practices"
steps:
# 第 1 步:研究员做调研,输出 JSON 格式的调研结果
- id: research
pipeline: >
openclaw.invoke --tool llm-task --action json
--args-json '{"prompt": "Research the latest information about ${topic}. Return key findings, data points, and sources.", "thinking": "medium"}'
# 第 2 步:写手基于调研结果写文章,上一步的输出通过 stdin 传入
- id: write
pipeline: >
openclaw.invoke --tool llm-task --action json
--args-json '{"prompt": "Write a 2000-word technical article based on the research provided via stdin.", "thinking": "high"}'
stdin: $research.json
# 第 3 步:人工审批——流水线暂停,等你确认
- id: review
approval: "Article draft is ready. Review before publishing?"
stdin: $write.json
# 第 4 步:审批通过后才执行发布
- id: publish
command: hugo --minify
when: $review.approved
关键语法解释:
pipeline:— 调用 Lobster 内置命令(如openclaw.invoke调用 Agent 工具)command:或run:— 执行普通 shell 命令stdin: $stepId.json— 把上一步的 JSON 输出传给下一步的标准输入,这就是数据在步骤之间流转的方式approval:— 人工审批门控,流水线暂停等待确认when:— 条件执行,只有满足条件才运行这一步
第三步:运行工作流
有两种触发方式:
方式 1:命令行直接跑
lobster run blog-pipeline.lobster --args-json '{"topic": "multi-agent cost optimization"}'
方式 2:Agent 在对话中触发
当你对 Supervisor 说"帮我写一篇关于多 Agent 成本优化的文章"时,Supervisor 可以调用 Lobster 工具:
{
"action": "run",
"pipeline": "/path/to/blog-pipeline.lobster",
"argsJson": "{\"topic\": \"multi-agent cost optimization\"}",
"timeoutMs": 60000
}
执行过程是什么样的
- Lobster 按顺序执行
research→write步骤,每一步调用对应的 LLM 处理 - 走到
review步骤时,流水线暂停,返回状态needs_approval和一个resumeToken - 你检查文章草稿,决定是否继续
- 如果满意,调用 resume 继续:
{"action": "resume", "token": "<resumeToken>", "approve": true} - 流水线继续执行
publish步骤
整个过程中,OpenClaw 只发起了一次 Lobster tool call。相比之下,用 sessions_send 做同样的事情,Supervisor 需要分别调用 Researcher、等回复、再调用 Writer、等回复、再汇总——至少 6 次 API 调用。
Lobster 与多 Agent 的关系
一个常见的误解:Lobster 是不是替代了多 Agent?不是。 Lobster 是多 Agent 的粘合剂:
- 多 Agent 负责能力隔离——每个 Agent 有自己的 SOUL.md、记忆、模型
- Lobster 负责流程编排——决定谁先执行、谁后执行、什么条件跳过、什么时候要人审批
sessions_send负责动态通信——Agent 需要根据运行时信息判断"接下来问谁”
三者不是互斥的,而是各管各的层次。大多数场景下,bindings 路由 + Lobster 流水线就够了;只有确实需要 LLM 动态判断的环节,才引入 sessions_send。
“这跟写 Skill 有什么区别?”
如果你也有这个疑问,说明你抓住了核心。Lobster 和 Skill(SOUL.md/AGENTS.md 里的指令)表面上都是"把流程写下来",但执行者完全不同:
Skill 是给 LLM 看的说明书。 你在 SOUL.md 里写"第一步调研,第二步写作,第三步审核",LLM 读了、理解了,然后自己决定怎么执行。它可能跳过第三步(“我觉得这篇不需要审核”),可能把第一步和第二步合并(“我一边搜一边写吧”),也可能做完第二步忘了第一步的完整输出。LLM 是在"理解指令",不是在"执行代码"。
Lobster 是给机器执行的脚本。 $research.json 通过 stdin 管道传给 $write,这不是 LLM “记住了上一步的结果”,而是操作系统级别的数据流传输。步骤不会被跳过,顺序不会被改变,审批是真正的 pause/resume(带 token),不是 LLM “假装暂停等一下”。
这个区别在三个场景下特别明显:
跨 Agent 调度。 Skill 只活在一个 Agent 的工作区里。你在 Writer 的 SOUL.md 里写"先让 Researcher 调研",Writer 自己做不到——它没有权限调度其他 Agent。Lobster 在 Gateway 层面执行,天然支持跨 Agent 调用。
审批门控。 Skill 里写"关键操作前询问用户确认",LLM 可能"觉得"这次不需要确认就直接做了。Lobster 的 approval: 是硬暂停——运行时序列化整个工作流状态,返回 resumeToken,不 resume 就永远不会继续。你的敏感操作绝不会被 LLM 的"好意"跳过。
上下文成本。 Skill 的每一步都在同一个 LLM 上下文窗口里累积,上下文越长每次调用越贵。Lobster 的步骤是独立的 tool call,上一步完成后输出通过管道传给下一步,不会无限膨胀上下文。
但不是所有场景都需要 Lobster。 如果流程完全在单个 Agent 内部(比如"搜索→总结→回复"这种三步操作),写在 SOUL.md 里就够了,杀鸡不用牛刀。Lobster 真正发力的地方是:跨 Agent 多步流程 + 需要硬性保证的执行顺序 + 审批门控 + token 成本敏感。
方案 B:sessions_send(动态 LLM 编排)
如果你的场景需要 Agent 根据运行时信息动态决定"接下来问谁",才需要 sessions_send。
在 openclaw.json 中开启:
{
"tools": {
"agentToAgent": {
"enabled": true,
"allow": ["supervisor", "writer", "coder", "researcher"],
"maxPingPongTurns": 3
}
}
}
| 参数 | 默认值 | 说明 |
|---|---|---|
enabled | false | 总开关,默认关闭 |
allow | [] | 允许通信的 Agent ID 白名单 |
maxPingPongTurns | 5 | 最大乒乓对话轮数(建议设 2-3) |
防递归规则(必配!)——必须在 Supervisor 的 SOUL.md 中写明:
## 协调规则
- 绝对不接受专家 Agent 回传的任务
- 收到专家的输出后,只做汇总和收尾,不再二次分发
- 如果专家完不成任务,直接向用户报告失败,不要换个说法重试
不加这条规则的后果很严重。Cogent 的多 Agent 故障报告记录了三种典型失败模式:无限循环(指令冲突的 Agent 互相推球)、幻觉共识(多个 Agent 收敛到一个编造的数据点,输出看起来自信但完全错误)、资源死锁(Agent 互相等待对方的输出)。其中无限循环最常见,也最烧钱。
另外一个实用的治理技巧来自 LumaDock 的多 Agent 治理指南:直接禁止专家 Agent 使用 sessions_send。研究员和程序员不需要主动联系其他 Agent,它们只需要接收任务、完成任务、返回结果。物理上禁止通信比在 prompt 里写"不要循环委派"可靠得多。
选哪个?决策框架
| 场景 | 用 Lobster | 用 sessions_send |
|---|---|---|
| 固定流程(调研→写作→审核) | ✅ | ❌ |
| 需要审批门控 | ✅ | ❌ |
| token 成本敏感 | ✅ | ❌ |
| 需要动态判断"问谁" | ❌ | ✅ |
| 需要多轮对话协商 | ❌ | ✅ |
| 完全即兴的探索性任务 | ❌ | ✅ |
我的建议:从 Lobster 起步。大多数看起来需要"动态编排"的场景,仔细分析后都能拆成确定性步骤。只有当你确实遇到了"事先无法预知下一步该问谁"的情况,才引入 sessions_send。
第五步:工具权限和沙箱
每个 Agent 只给它需要的工具。权限过多不仅有安全风险,还会让模型在过多工具选项中迷失——工具越多,选择准确率越低。
{
agents: {
list: [
{
id: "writer",
workspace: "~/openclaw-agents/writer",
sandbox: {
enabled: true,
allowedPaths: ["~/writing/", "~/drafts/"]
},
tools: {
allow: ["tavily-search", "memory_search", "read", "write"],
deny: ["exec", "browser", "shell"]
}
},
{
id: "coder",
workspace: "~/openclaw-agents/coder",
sandbox: {
enabled: true,
allowedPaths: ["~/projects/"]
},
tools: {
allow: ["exec", "read", "write", "browser", "memory_search"],
deny: ["tavily-search"]
}
},
{
id: "researcher",
workspace: "~/openclaw-agents/researcher",
tools: {
allow: ["tavily-search", "memory_search", "read"],
deny: ["exec", "write", "browser", "shell", "sessions_send"]
}
}
]
}
}
注意最后一个 researcher 的配置:我在 deny 里显式加了 sessions_send。这不是因为研究员不需要跟人说话,而是为了物理上阻止循环委派。研究员只需要接收任务、做调研、返回结果,不需要主动联系其他 Agent。
沙箱配置速查
| Agent 类型 | 文件权限 | 工具权限 | 核心原则 |
|---|---|---|---|
| 写手 | 只读写内容目录 | 搜索+读写 | 禁止执行命令 |
| 程序员 | 限制在项目目录 | 全部开发工具 | 限制目录范围 |
| 研究员 | 无写权限 | 仅搜索工具 | 只读不写,禁止 sessions_send |
| 家庭/共享 | 只读沙箱 | 仅回答问题 | 不能修改任何东西 |
更多工具权限技巧,参考 OpenClaw 自动化避坑指南。
飞书集成:企业级多 Agent 部署
飞书是国内企业用得最多的办公平台。OpenClaw 从 2026.2.26 起内置飞书 Channel,2026.3.13 起完整支持多 Agent 路由。
架构:一个机器人对应一个 Agent
推荐做法:在飞书开放平台创建多个机器人应用,每个机器人绑定一个 Agent。
第一步:创建飞书机器人
- 打开 飞书开放平台 → 创建企业自建应用
- 为每个 Agent 创建一个机器人:
工作助手(supervisor)、写作助手(writer)、代码助手(coder) - 获取每个机器人的 App ID 和 App Secret
第二步:配置权限
每个机器人至少需要这些 Scopes:
| 权限 | 说明 |
|---|---|
im:message | 收发消息 |
im:message.group_at_msg | 接收群内 @消息 |
contact:user.base:readonly | 读取用户信息 |
根据 Agent 需要额外添加:docs:doc(文档)、calendar:calendar(日历)、task:task(任务)、bitable:app(多维表格)。
第三步:配置 openclaw.json
{
channels: {
feishu: [
{
account: "work-bot",
appId: "cli_xxx_work",
appSecret: "your_work_secret"
},
{
account: "writing-bot",
appId: "cli_xxx_write",
appSecret: "your_write_secret"
},
{
account: "code-bot",
appId: "cli_xxx_code",
appSecret: "your_code_secret"
}
]
},
bindings: [
{
agentId: "supervisor",
match: { channel: "feishu", accountId: "work-bot" }
},
{
agentId: "writer",
match: { channel: "feishu", accountId: "writing-bot" }
},
{
agentId: "coder",
match: { channel: "feishu", accountId: "code-bot" }
}
]
}
第四步:启动并验证
openclaw gateway restart
openclaw channels status --probe
openclaw agents list --bindings
飞书的独特优势
- 不需要公网地址——飞书使用 WebSocket 事件订阅,OpenClaw 主动连接飞书服务器
- 消息卡片反馈——显示「思考中/生成中/完成」状态
- 企业能力集成——Agent 可以直接操作飞书文档、日历、任务、多维表格
- 敏感操作确认——关键操作弹确认按钮,用户确认后才执行
四种协作模式与选型
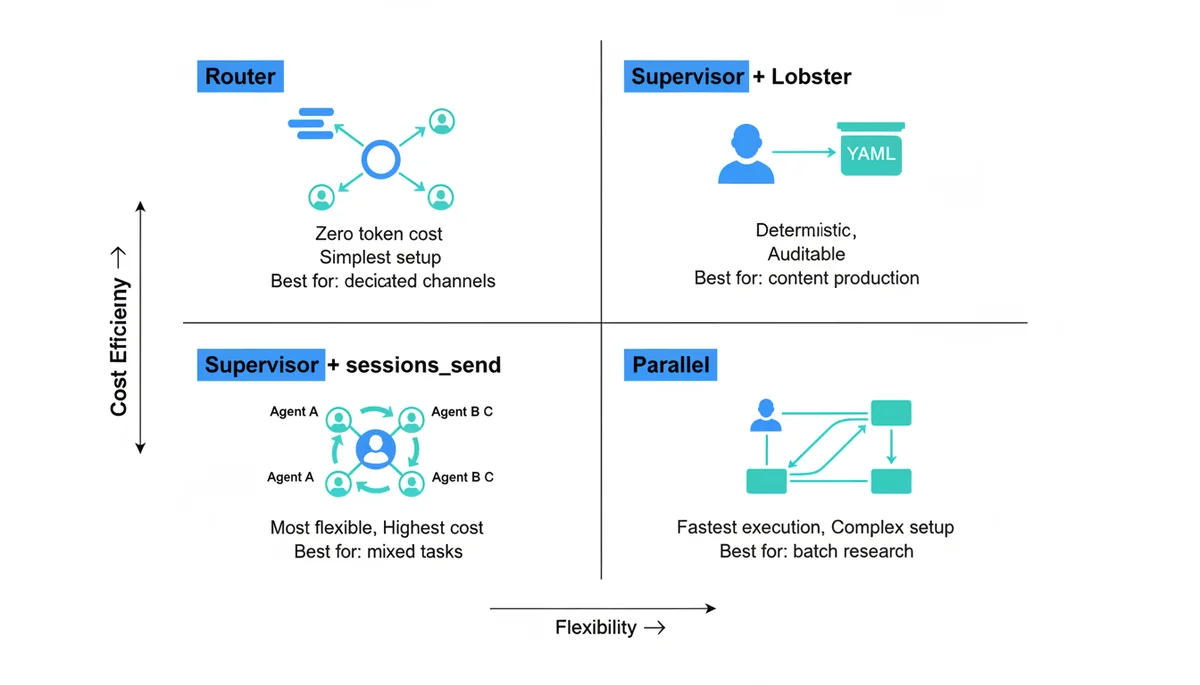
模式一:Router(推荐起步)
Telegram 写作群 → Writer
Telegram 代码群 → Coder
飞书工作机器人 → Supervisor
通过 bindings 把不同频道/群组的消息直接路由到对应 Agent。零额外 token 消耗——不需要 Supervisor 中转,不需要 Agent 间通信。
这是我推荐的第一步。大多数人的使用场景天然按频道分隔——写作群里聊的就是写作,代码群里聊的就是代码。不需要一个"全知全能"的 Supervisor 来做分发。
模式二:Supervisor + Lobster
用户 → Supervisor → [Lobster 流水线] → Writer → Reviewer → 用户
Supervisor 接收请求,触发 Lobster 流水线,流水线内部的步骤是确定性的。适合有固定流程的场景:内容生产、代码审查链、数据处理。
模式三:Supervisor + sessions_send
用户 → Supervisor → Writer / Coder / Researcher → Supervisor → 用户
Supervisor 用 LLM 判断该委派给谁,通过 sessions_send 动态通信。灵活性最高,成本也最高。适合无法预定义流程的混合领域任务。
模式四:Parallel(并行执行)
→ Researcher A(主题1)
用户 → Supervisor → Researcher B(主题2) → Supervisor → 用户
→ Researcher C(主题3)
把大任务拆成多个子任务并行执行。适合大规模调研、多文件代码生成、批量处理。配置复杂度最高,需要仔细的结果聚合和错误处理。
选型速查
| 场景 | 推荐模式 | 原因 |
|---|---|---|
| 各群各司其职 | Router | 零开销,最简单 |
| 博客内容生产 | Supervisor + Lobster | 确定性流水线,可审计 |
| 个人全能助手 | Supervisor + sessions_send | 灵活路由,但成本高 |
| 10 家竞品同时分析 | Parallel | 并行提速 |
成本控制:5 个立即可用的策略
多 Agent 意味着 API 成本倍增。Deloitte 预测超过 40% 的 agentic AI 项目可能因成本失控被取消。以下策略可以帮你省 60-80%:
1. Supervisor 用便宜模型。 它只做路由决策,Haiku 就够了。把 Sonnet/Opus 留给干活的专家 Agent。
2. 能用 Router 就不用 Supervisor。 bindings 路由没有任何 token 开销。如果你的频道/群组天然对应不同 Agent,直接用 bindings 路由。
3. 用 Lobster 替代 sessions_send。 确定性流水线一次 tool call 搞定,比 LLM 多次编排调用省一个数量级的 token。
4. 限制乒乓轮数。 maxPingPongTurns 默认是 5,但大多数场景 2-3 轮就够了。每多一轮就是两次 API 调用。
5. 简单问题直接答。 在 Supervisor 的 SOUL.md 里写明:“一句话能答完的问题直接回答,不要委派给专家。“避免一个"今天天气怎么样"也触发一次 sessions_send。
更多记忆层面的成本优化,参考 OpenClaw 记忆策略指南。
常见问题排查
Agent 收不到消息
检查 binding 优先级。用 openclaw agents list --bindings 查看实际路由顺序。一个更宽泛的 binding(比如 channel 级默认)可能在你的精确 peer 规则之前截获了消息——确保精确规则在配置文件中靠前。
sessions_send 静默失败
两个最常见的原因:1)目标 Agent 不在 agentToAgent.allow 白名单中;2)Agent 间通信的总开关 enabled 还是 false。默认是关闭的,必须手动开启。
Agent 更新后"变笨了”
这是 2026.3.2 版本的已知问题。更新后所有工具权限被重置为默认关闭。解决方法:在 openclaw.json 的 agents.list[].tools.allow 中显式列出每个 Agent 需要的工具。
Token 成本飙升
首先检查 Supervisor 是不是在用贵的模型做路由。然后用 /status 或 openclaw sessions --json 查看每个 Agent 的 token 消耗分布。如果某个 Agent 的消耗远超预期,检查是否存在循环委派——看日志里有没有同一对 Agent 之间反复出现的 sessions_send 调用。
推荐起步配置
大多数个人用户,从这个 3 Agent 配置开始就够了:
| Agent | 模型 | 角色 | 绑定 |
|---|---|---|---|
| supervisor | claude-3.5-haiku | 路由分发 + 简单问答 | 所有频道的默认 |
| writer | deepseek-r1 | 写文章、文档、邮件 | 写作专用群/频道 |
| coder | claude-sonnet-4 | 写代码、调试、代码审查 | 代码专用群/频道 |
当你发现 Supervisor 频繁需要做网络搜索时,加一个 researcher Agent。只有在确实有明确分工需求时才加更多专家——一个配置精良的 3 Agent 团队比混乱的 10 Agent 团队强得多。Reddit 上一位用户的原话说得好:“Run them like human coworker, tune it to use product, but not the product itself.”
相关阅读
多 Agent 配置只是起点。配好之后继续探索:
- OpenClaw Tavily 集成指南——给研究员 Agent 加上实时网络搜索
- OpenClaw 使用教程——从零开始的新手指南
- OpenClaw 安装配置指南——完整安装和基础配置
- Lobster 工作流引擎——用 YAML 编排确定性多 Agent 流水线
- OpenClaw ACP——把 IDE 桥接到 OpenClaw Agent 的编码工作流
Comments
Join the discussion — requires a GitHub account