从零开始用 Python 构建你自己的 Claude Code(仅 250 行)
一篇实战教程,通过用 Python 从零重建 Claude Code 的核心架构——Agentic Loop、Tool Use 和流式输出,彻底揭开 AI 编程助手的神秘面纱。从 20 行代码到完整的终端 AI 编程助手。
Claude CodePythonAgentic LoopTool UseAI Agent
2437 字
2026-02-24 02:00 +0000
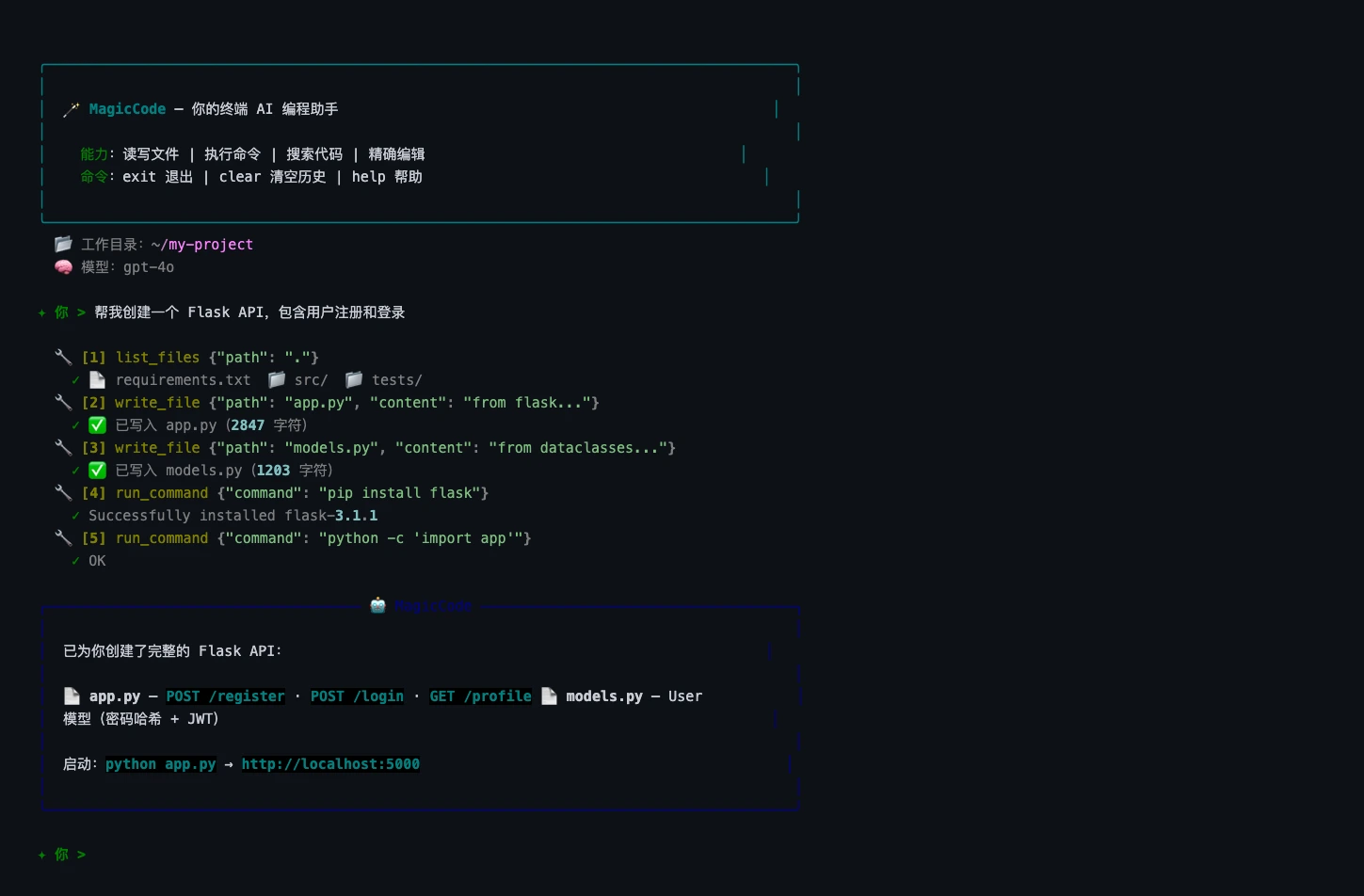
你可能用过 Claude Code,或者至少听过关于它的各种传说。它能读懂你的代码库、写文件、跑测试、修 bug——全部在终端里完成。用起来像魔法一样。
但事实是:它背后的核心架构出奇地简单。 简单到你可以在一个下午用 Python 和大约 250 行代码从零重建它。
这正是本文要做的事。我们将构建 MagicCode——一个终端 AI 编程助手,能够读取文件、编写代码、执行 shell 命令,并做出自主的多步决策——就像 Claude Code 底层的工作方式一样。
更重要的是,读完本文后,你将深刻理解驱动每一个现代 AI 编程工具的三个核心概念:
- Agentic Loop(智能体循环) ——让 AI 自主行动的决策引擎
- Tool Use(工具调用 / Function Calling) ——LLM 与真实世界交互的方式
- 消息协议 ——带工具调用的对话在 API 层面究竟是怎样运作的
我们将逐步迭代:V1(基础聊天,20 行)→ V2(流式输出)→ V3(精美终端 UI)→ V4(完整工具系统 + Agentic Loop,250 行)。每个版本在上一个的基础上递进。没有含糊其辞,没有黑魔法——只有你可以直接运行的代码。
为什么要自己造一个?
用工具是一回事,理解它是怎么工作的是另一回事。
当你理解了 Claude Code 背后的架构,你就获得了定制它、扩展它、或者基于同样的原理构建完全不同产品的能力。所有 AI 编程工具——Claude Code、Cursor Agent、Copilot Workspace、Windsurf、Cline——本质上都运行在相同的架构之上。学会一次,全部理解。
架构解析:Claude Code 到底特别在哪?
在写任何代码之前,先回答一个根本性的问题:Claude Code 和普通聊天机器人的区别到底是什么?
答案只有两个字:工具调用。
普通聊天机器人 vs. AI 编程智能体
普通聊天机器人是这样工作的:
你:帮我写一个 hello world 程序。
AI:好的!代码如下:print("hello world")
你:(手动复制粘贴到编辑器,保存,运行)
AI 编程智能体是这样工作的:
你:帮我写一个 hello world 程序。
AI:(创建 hello.py → 写入代码 → 运行 → 报告结果)
区别在于?AI 不只是说——它还能做。 它拥有工具(读文件、写文件、执行命令),并且能自主决定何时以及如何使用这些工具。
Agentic Loop(智能体循环)
Claude Code——以及每一个 AI 编程智能体——的灵魂是一种叫做 Agentic Loop 的模式:
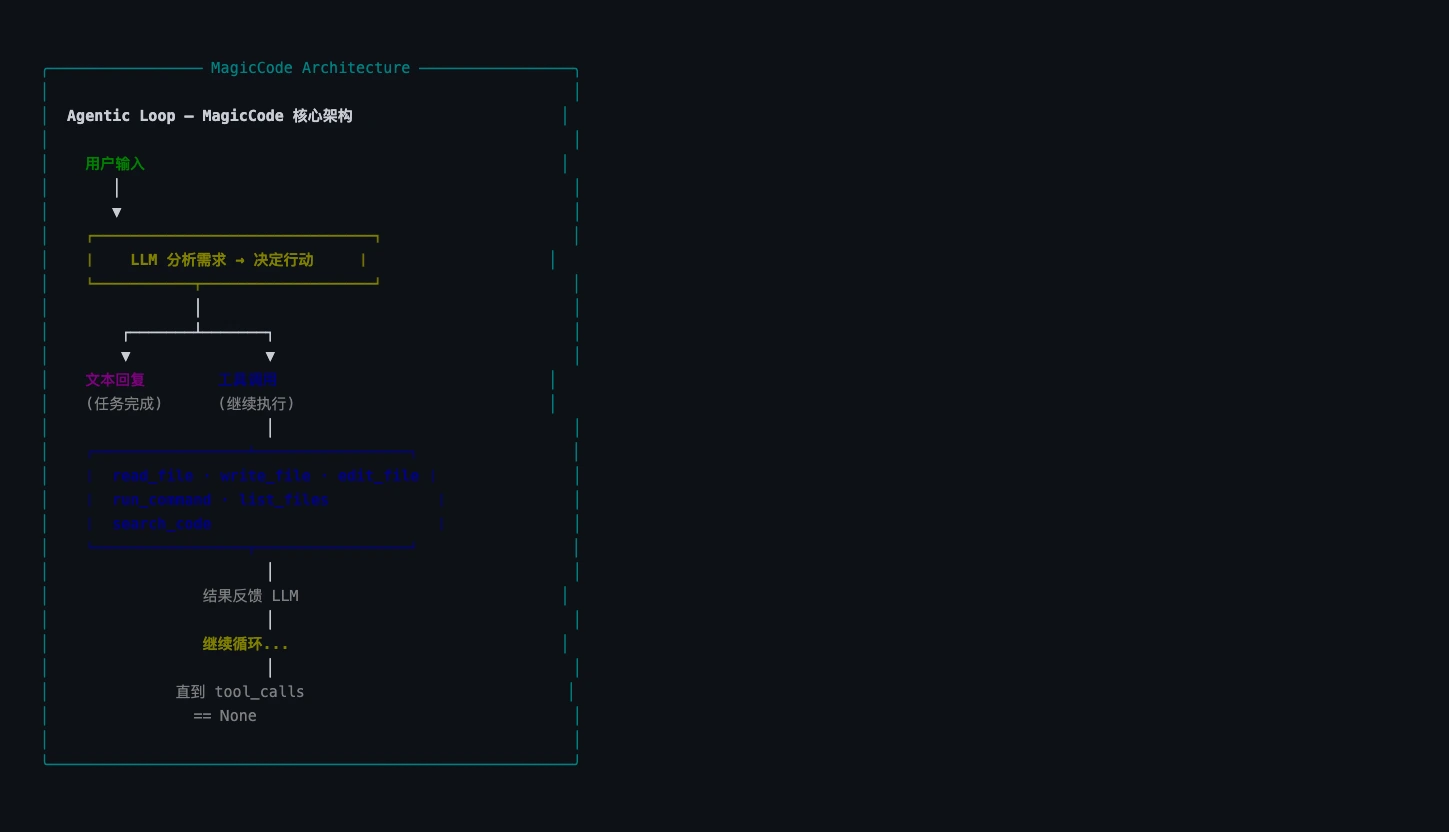
它的工作方式是这样的:
- 用户发送消息 → 转发给 LLM
- LLM 思考 → 决定是直接回复还是先使用工具
- 如果使用了工具 → 你的代码执行工具并将结果发回
- LLM 再次思考 → 可能使用另一个工具,可能直接回复
- 重复步骤 3–4 → 直到 LLM 判断任务完成
这就是 Claude Code 能处理复杂多步任务的原因。它不会给你一个一次性的答案。相反,它像开发者一样工作:看代码、思考该做什么、做出修改、验证是否有效、继续循环。 循环持续进行直到任务完成。
Tool Use / Function Calling 是如何工作的
OpenAI 和 Anthropic 的 API 都原生支持 Tool Use(OpenAI 称之为 “Function Calling”)。机制很直接:
- 你定义一组工具(名称、描述、参数)并传给 API
- LLM 可以选择在其回复中调用一个或多个工具(返回
tool_calls数组) - 你的代码执行工具并将结果发回(作为
role: "tool"消息) - LLM 利用结果继续推理
关键洞察:AI 永远不会自己执行工具。 它只决定调用哪个工具以及传什么参数。实际执行发生在你的 Python 代码里。这正是架构安全的基石——你完全掌控执行边界。
环境准备
前置条件
- Python 3.10+(推荐 3.12+)
- 一个 OpenAI API key(platform.openai.com)
- 一个终端(iTerm2、Terminal.app、Windows Terminal——都可以)
项目初始化
mkdir magiccode && cd magiccode
python3 -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install openai rich prompt_toolkit
三个依赖,各有明确用途:
| 库 | 用途 | 原因 |
|---|---|---|
openai | OpenAI Python SDK | 原生支持 Function Calling 的 API 调用 |
rich | 终端 UI | Markdown 渲染、语法高亮、面板 |
prompt_toolkit | 增强输入 | 历史记录、自动补全(可选但推荐) |
配置 API Key
export OPENAI_API_KEY="sk-your-key-here"
提示:把这行加到
~/.zshrc或~/.bashrc里,这样就不用每次都手动设置了。
V1:20 行代码的基础版
构建任何复杂东西的最佳方式是从简单到令人尴尬的版本开始。V1 只是一个聊天循环——没有流式输出,没有工具,没有炫酷 UI。20 行代码,证明核心 API 调用能跑通。
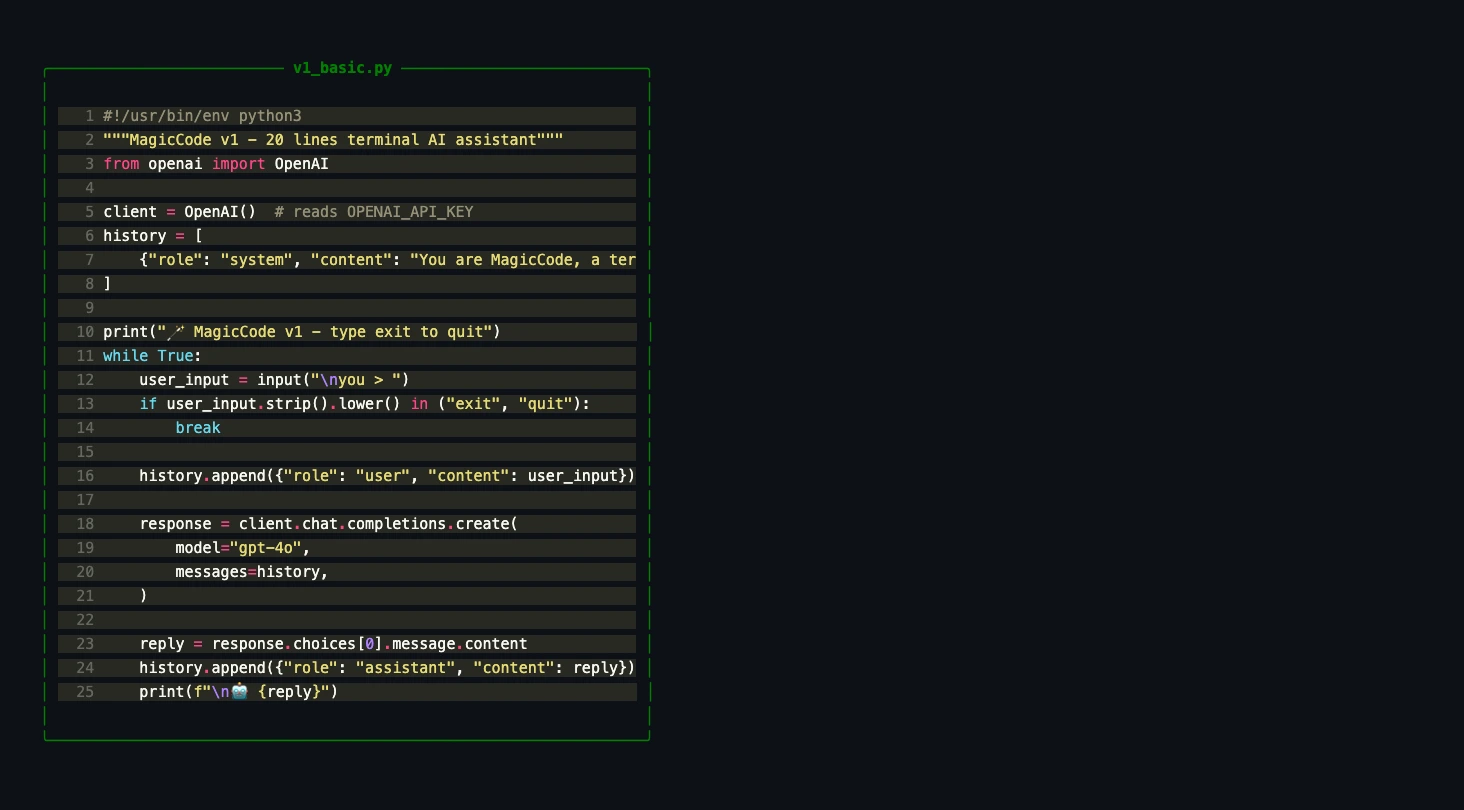
#!/usr/bin/env python3
"""MagicCode v1 — 一个 20 行的终端 AI 助手。"""
from openai import OpenAI
client = OpenAI() # 从环境变量读取 OPENAI_API_KEY
history = [{"role": "system", "content": "You are MagicCode, a terminal AI coding assistant. Be concise and helpful."}]
print("🪄 MagicCode v1 — 输入 'exit' 退出")
while True:
user_input = input("\nYou > ")
if user_input.strip().lower() in ("exit", "quit"):
break
history.append({"role": "user", "content": user_input})
response = client.chat.completions.create(
model="gpt-4o",
messages=history,
)
reply = response.choices[0].message.content
history.append({"role": "assistant", "content": reply})
print(f"\n🤖 {reply}")
保存为 v1_basic.py 然后运行:
python v1_basic.py
它能跑。它是一个可用的 AI 聊天助手。但它只能说——不能做任何事。就像一个能制定战略却没有军队的参谋。
值得理解的核心概念
history 列表就是对话记忆。每条用户消息和 AI 回复都会追加进去,每次 API 调用时整个列表都会被发送。这就是 LLM “记住"上下文的方式——没有什么魔法般的持久化,只是一个不断增长的消息数组。(这也是为什么长对话最终会撞到 token 限制且费用越来越高。)
system 消息定义了 AI 的角色和行为规则。它在编程上等同于 Claude Code 的 CLAUDE.md——告诉模型它是谁以及该如何行动。在 OpenAI 的 API 中,它是 messages 列表中的第一条消息。
V2:流式输出——打字机效果
V1 有一个体验问题:在生成长回复时,你盯着一个空白终端等模型生成完整回复,然后所有答案一次性出现。这感觉像是坏了。
流式输出解决了这个问题。API 在生成 token 时就立即发送,所以回复会逐字出现——就像看着有人实时打字。
#!/usr/bin/env python3
"""MagicCode v2 — 带流式输出。"""
from openai import OpenAI
client = OpenAI()
history = [{"role": "system", "content": "You are MagicCode, a terminal AI coding assistant. Be concise and professional."}]
print("🪄 MagicCode v2(流式输出)— 输入 'exit' 退出")
while True:
user_input = input("\nYou > ")
if user_input.strip().lower() in ("exit", "quit"):
break
history.append({"role": "user", "content": user_input})
print("\n🤖 ", end="", flush=True)
full_reply = ""
stream = client.chat.completions.create(
model="gpt-4o",
messages=history,
stream=True, # ← 关键改动
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="", flush=True)
full_reply += delta
print() # 回复结束后换行
history.append({"role": "assistant", "content": full_reply})
改动很小:设置 stream=True,然后遍历 chunks 并在每个 delta.content 到达时打印出来。
flush=True比你想象的更重要。没有它,Python 会缓冲输出,你看到的文字会一段一段蹦出来,而不是流畅的逐字显示。它强制 Python 立刻将每个字符写入终端。
V3:精美终端——Rich Markdown 渲染
终端不一定要丑。借助 rich 库,我们可以在终端里渲染带语法高亮的 Markdown、格式化表格、彩色面板和漂亮的排版。
#!/usr/bin/env python3
"""MagicCode v3 — Rich Markdown 渲染与实时流式输出。"""
from openai import OpenAI
from rich.console import Console
from rich.markdown import Markdown
from rich.panel import Panel
from rich.live import Live
client = OpenAI()
console = Console()
history = [{"role": "system", "content": "You are MagicCode, a terminal AI coding assistant. Format responses in Markdown."}]
console.print(Panel(
"🪄 [bold cyan]MagicCode v3[/] — 终端 AI 编程助手\n输入 'exit' 退出",
border_style="cyan"
))
while True:
console.print()
user_input = console.input("[bold green]You >[/] ")
if user_input.strip().lower() in ("exit", "quit"):
break
history.append({"role": "user", "content": user_input})
full_reply = ""
stream = client.chat.completions.create(
model="gpt-4o", messages=history, stream=True,
)
with Live(console=console, refresh_per_second=8) as live:
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
full_reply += delta
live.update(Panel(
Markdown(full_reply),
title="🤖 MagicCode",
border_style="blue",
))
history.append({"role": "assistant", "content": full_reply})
Rich.Live 组件会在新内容流入时持续重新渲染面板。你可以看着 Markdown 表格、代码块和格式化文本实时呈现——就像看着一份文档在你眼前被书写。
V4:工具系统——给 AI 装上双手
前三个版本是逐步打磨的聊天机器人。现在我们给 AI 赋予真正的能力——读文件、写文件和执行命令。从这里开始,它不再是聊天机器人,而是一个智能体。
这是本文最重要的部分。
定义工具
OpenAI 的 Function Calling 要求工具定义遵循特定的 JSON Schema 格式。每个工具需要名称、描述和参数模式:
TOOLS = [
{
"type": "function",
"function": {
"name": "read_file",
"description": "Read the contents of a file. Returns the content with line numbers.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "File path to read"
}
},
"required": ["path"],
},
},
},
{
"type": "function",
"function": {
"name": "write_file",
"description": "Write content to a file. Creates parent directories if needed.",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "File path"},
"content": {"type": "string", "description": "Complete file content"},
},
"required": ["path", "content"],
},
},
},
{
"type": "function",
"function": {
"name": "run_command",
"description": "Execute a shell command. Times out after 30 seconds.",
"parameters": {
"type": "object",
"properties": {
"command": {"type": "string", "description": "Shell command to execute"}
},
"required": ["command"],
},
},
},
{
"type": "function",
"function": {
"name": "list_files",
"description": "List directory contents (ignores node_modules, .git, etc.).",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "Directory path", "default": "."},
},
"required": [],
},
},
},
]
工具定义比你想象的更重要。模型会阅读这些描述来决定何时以及如何使用每个工具。好的描述带来更准确的工具选择。几个原则:
- 直观的名称:
read_file一看就懂;rf则不然 - 具体的描述:模型用这些来判断何时该使用某个工具
- 精确的参数模式:必填 vs. 可选、类型和默认值都会影响模型的行为
实现工具执行
AI 决定调用什么工具、传什么参数。你的代码负责实际执行。 这种分离是整个架构安全性的基石——你完全控制实际发生的事情:
import os
import subprocess
def execute_tool(name: str, params: dict) -> str:
"""执行工具调用并以字符串形式返回结果。"""
try:
if name == "read_file":
with open(params["path"], "r", encoding="utf-8") as f:
content = f.read()
lines = content.split("\n")
# 添加行号,方便 AI 后续引用特定位置
numbered = "\n".join(
f"{i+1:4d} | {line}" for i, line in enumerate(lines)
)
return f"📄 {params['path']} ({len(lines)} lines)\n{numbered}"
elif name == "write_file":
path = params["path"]
os.makedirs(os.path.dirname(path) or ".", exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(params["content"])
return f"✅ Written to {path} ({len(params['content'])} chars)"
elif name == "run_command":
cmd = params["command"]
# 🛡️ 安全检查:阻止危险命令
dangerous = ["rm -rf /", "mkfs", "dd if=", "> /dev/sd"]
if any(d in cmd for d in dangerous):
return "❌ Refused to execute dangerous command"
result = subprocess.run(
cmd, shell=True, capture_output=True,
text=True, timeout=30
)
output = result.stdout
if result.stderr:
output += "\n--- stderr ---\n" + result.stderr
return output.strip() or "(Command completed with no output)"
elif name == "list_files":
path = params.get("path", ".")
entries = sorted(os.listdir(path))
result = []
for entry in entries:
full = os.path.join(path, entry)
icon = "📁" if os.path.isdir(full) else "📄"
result.append(f"{icon} {entry}")
return "\n".join(result) or "Empty directory"
except Exception as e:
return f"❌ {type(e).__name__}: {e}"
这里有几个值得注意的设计决策:
read_file返回带行号的内容:这让 AI 在后续需要编辑文件时可以精确引用位置——正是 Claude Code 的 Read 工具的工作方式。write_file自动创建目录:os.makedirs(exist_ok=True)消除了"目录不存在"的错误。AI 不应该操心创建父目录。run_command有安全黑名单:简单但有效地防范破坏性操作。(关于 AI 编程安全的深入探讨,参见 安全的 Vibe Coding。)- 所有工具返回字符串:这是 API 的要求——工具结果必须是可序列化的文本。
Agentic Loop——一切的核心
这是整个项目的灵魂。不到 40 行代码,实现了自主决策、多步工具执行和自主完成任务的完整循环:
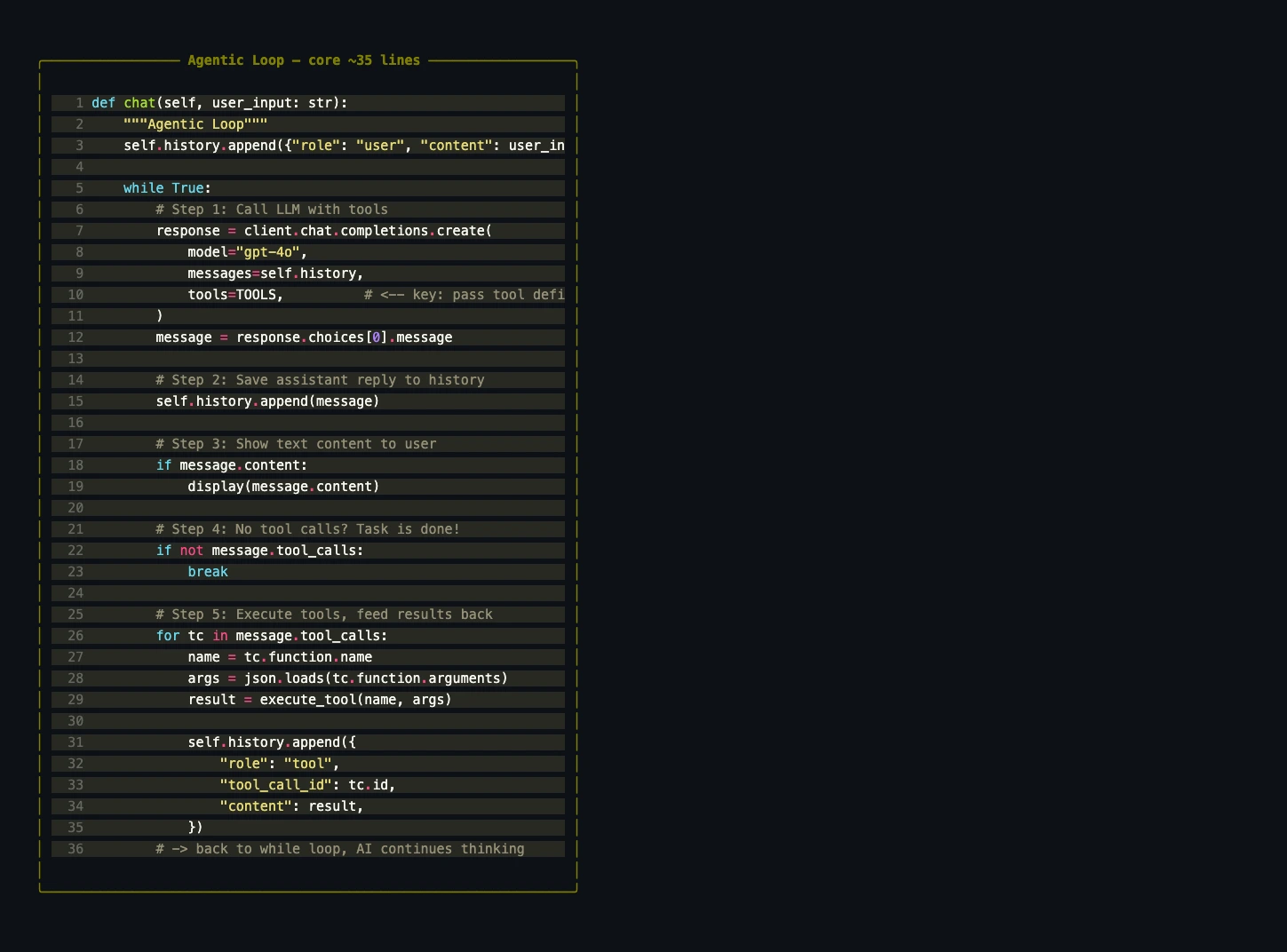
def chat(user_input: str):
"""Agentic Loop:AI 自主决策循环。"""
history.append({"role": "user", "content": user_input})
while True:
# 1️⃣ 带工具定义调用 LLM
response = client.chat.completions.create(
model="gpt-4o",
messages=history,
tools=TOOLS, # ← 传入工具定义
)
message = response.choices[0].message
# 2️⃣ 将 AI 的完整响应存入历史
history.append(message)
# 3️⃣ 显示文本内容
if message.content:
console.print(Panel(Markdown(message.content), title="🤖 MagicCode"))
# 4️⃣ 没有工具调用?任务完成——退出循环
if not message.tool_calls:
break
# 5️⃣ 执行每个工具调用并将结果反馈回去
for tool_call in message.tool_calls:
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
console.print(f" 🔧 {name}({args})")
result = execute_tool(name, args)
# 以 role="tool" 消息发送工具结果
history.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result,
})
# → 回到 while 循环顶部——AI 继续思考
精妙之处在于 while True 循环。 单个 AI 回复可以同时包含文本和工具调用。以下是真实的多轮执行过程:
AI 第 1 轮:
content: "让我先看看项目结构。"
tool_calls: [list_files("."), read_file("package.json")]
→ 执行工具,将结果发回 AI
AI 第 2 轮:
content: "这是一个 Node.js 项目。我来修改入口文件..."
tool_calls: [write_file("index.js", ...)]
→ 执行工具,将结果发回 AI
AI 第 3 轮:
content: "完成了。让我用测试验证一下。"
tool_calls: [run_command("npm test")]
→ 执行工具,将结果发回 AI
AI 第 4 轮:
content: "✅ 所有测试通过。以下是我做的改动..."
tool_calls: null → 循环退出
一个用户请求可以触发十几次工具调用,每一次都基于上一次的结果。AI 规划、行动、观察、调整——自主进行。这就是 “agentic” 的含义。模型不只是在回答问题;它在完成任务。
消息协议——实际发生了什么
理解消息格式对调试至关重要。发送给 API 的 history 数组看起来是这样的:
[
# System 消息——定义 AI 的行为
{"role": "system", "content": "You are MagicCode..."},
# 用户消息
{"role": "user", "content": "帮我写一个 hello world 程序"},
# AI 回复——包含工具调用
{
"role": "assistant",
"content": "我来帮你创建这个文件。",
"tool_calls": [{
"id": "call_abc123",
"type": "function",
"function": {
"name": "write_file",
"arguments": '{"path":"hello.py","content":"print(\'hello world\')"}'
}
}]
},
# 工具结果——通过 tool_call_id 匹配
{
"role": "tool",
"tool_call_id": "call_abc123",
"content": "✅ Written to hello.py (20 chars)"
},
# AI 继续推理
{
"role": "assistant",
"content": "文件已创建。让我运行一下。",
"tool_calls": [{
"id": "call_def456",
"type": "function",
"function": {"name": "run_command", "arguments": '{"command":"python hello.py"}'}
}]
},
# ... 循环继续
]
两个能帮你省下几小时调试时间的细节:
- 工具结果使用
role: "tool",不是role: "user"。模型对这两者的处理方式不同——它知道这些数据来自工具执行,而非人类。 tool_call_id必须精确匹配。 每个工具结果必须引用对应tool_call的id。如果不匹配,API 会拒绝请求。这是模型将结果映射到对应工具的方式。
完整源码:MagicCode 最终版
现在让我们把所有四个版本的能力整合到一个产品级的实现中。我们将额外添加两个工具(用于精确文本替换的 edit_file 和用于代码搜索的 search_code),一个防止无限循环的安全阀,以及干净的类结构。
以下是完整的 magic.py——大约 250 行:
#!/usr/bin/env python3
"""
MagicCode — 从零构建的终端 AI 编程助手。
特性:Tool Use | Markdown 渲染 | Agentic Loop
"""
import os
import json
import glob
import subprocess
from openai import OpenAI
from rich.console import Console
from rich.markdown import Markdown
from rich.panel import Panel
# ========== 配置 ==========
MODEL = os.getenv("MAGIC_MODEL", "gpt-4o")
client = OpenAI() # 从环境变量读取 OPENAI_API_KEY
SYSTEM_PROMPT = """You are MagicCode, a powerful terminal AI coding assistant.
## Your Tools
- read_file: Read file contents (with line numbers)
- write_file: Write to files (auto-creates directories)
- edit_file: Replace specific text in a file
- run_command: Execute shell commands (30s timeout)
- list_files: List directory structure
- search_code: Search for patterns in code
## Working Principles
1. Always read a file before modifying it
2. Break complex tasks into steps; verify each step
3. Never execute destructive commands (rm -rf, format, etc.)
4. Respond in Markdown format"""
# ========== 工具定义 ==========
def _fn(name, desc, params, required):
return {"type": "function", "function": {
"name": name, "description": desc,
"parameters": {"type": "object", "properties": params, "required": required},
}}
TOOLS = [
_fn("read_file", "Read file contents. Returns text with line numbers.",
{"path": {"type": "string", "description": "File path"}}, ["path"]),
_fn("write_file", "Write content to a file. Creates directories if needed.",
{"path": {"type": "string", "description": "File path"},
"content": {"type": "string", "description": "Complete file content"}}, ["path", "content"]),
_fn("edit_file", "Replace old_text with new_text in a file (first occurrence).",
{"path": {"type": "string", "description": "File path"},
"old_text": {"type": "string", "description": "Text to find"},
"new_text": {"type": "string", "description": "Replacement text"}}, ["path", "old_text", "new_text"]),
_fn("run_command", "Execute a shell command with 30-second timeout.",
{"command": {"type": "string", "description": "Shell command"}}, ["command"]),
_fn("list_files", "Recursively list directory structure (max 3 levels, ignores .git etc.).",
{"path": {"type": "string", "description": "Directory path"}}, []),
_fn("search_code", "Search for a pattern across all files in a directory.",
{"pattern": {"type": "string", "description": "Search pattern"},
"path": {"type": "string", "description": "Search directory"}}, ["pattern"]),
]
IGNORED_DIRS = {".git", "node_modules", "__pycache__", ".venv", "venv", "dist", "build"}
# ========== 工具执行 ==========
def execute_tool(name: str, params: dict) -> str:
try:
if name == "read_file":
with open(params["path"], "r", encoding="utf-8", errors="replace") as f:
content = f.read()
lines = content.split("\n")
numbered = "\n".join(f"{i+1:4d} | {line}" for i, line in enumerate(lines))
return f"📄 {params['path']} ({len(lines)} lines)\n{numbered}"
elif name == "write_file":
path = params["path"]
os.makedirs(os.path.dirname(path) or ".", exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(params["content"])
return f"✅ Written to {path} ({len(params['content'])} chars)"
elif name == "edit_file":
path = params["path"]
with open(path, "r", encoding="utf-8") as f:
content = f.read()
if params["old_text"] not in content:
return "❌ Target text not found in file"
new_content = content.replace(params["old_text"], params["new_text"], 1)
with open(path, "w", encoding="utf-8") as f:
f.write(new_content)
return f"✅ Edited {path}"
elif name == "run_command":
cmd = params["command"]
dangerous = ["rm -rf /", "mkfs", "dd if=", "> /dev/sd"]
if any(d in cmd for d in dangerous):
return "❌ Refused to execute dangerous command"
result = subprocess.run(
cmd, shell=True, capture_output=True, text=True, timeout=30
)
output = result.stdout
if result.stderr:
output += "\n--- stderr ---\n" + result.stderr
return output.strip() or "(No output)"
elif name == "list_files":
path = params.get("path", ".")
lines = []
def walk(d, prefix="", depth=0):
if depth >= 3: return
try: entries = sorted(os.listdir(d))
except PermissionError: return
for e in entries:
full = os.path.join(d, e)
if e in IGNORED_DIRS or e.startswith("."): continue
if os.path.isdir(full):
lines.append(f"{prefix}📁 {e}/")
walk(full, prefix + " ", depth + 1)
else:
lines.append(f"{prefix}📄 {e}")
walk(path)
return "\n".join(lines[:200]) or "Empty directory"
elif name == "search_code":
pattern = params["pattern"]
path = params.get("path", ".")
matches = []
for fp in glob.glob(os.path.join(path, "**", "*"), recursive=True):
if any(d in fp for d in IGNORED_DIRS) or not os.path.isfile(fp):
continue
try:
with open(fp, "r", encoding="utf-8", errors="replace") as f:
for i, line in enumerate(f, 1):
if pattern.lower() in line.lower():
matches.append(f"{fp}:{i}: {line.rstrip()}")
if len(matches) >= 50: break
except OSError: continue
if len(matches) >= 50: break
return "\n".join(matches) or f"No matches for '{pattern}'"
except Exception as e:
return f"❌ {type(e).__name__}: {e}"
# ========== Agentic Loop ==========
class MagicCode:
def __init__(self):
self.console = Console()
self.history = [{"role": "system", "content": SYSTEM_PROMPT}]
def chat(self, user_input: str):
self.history.append({"role": "user", "content": user_input})
tool_count = 0
while True:
response = client.chat.completions.create(
model=MODEL, messages=self.history, tools=TOOLS,
)
message = response.choices[0].message
self.history.append(message)
# 显示文本回复
if message.content:
self.console.print(Panel(
Markdown(message.content),
title="🤖 MagicCode", border_style="blue", padding=(1, 2),
))
# 没有工具调用 → 任务完成
if not message.tool_calls:
break
# 执行每个工具调用
for tc in message.tool_calls:
tool_count += 1
name = tc.function.name
args = json.loads(tc.function.arguments)
info = json.dumps(args, ensure_ascii=False)
if len(info) > 120: info = info[:120] + "..."
self.console.print(f" [yellow]🔧 [{tool_count}] {name}[/] [dim]{info}[/]")
result = execute_tool(name, args)
preview = result[:100].replace("\n", " ")
self.console.print(f" [green] ✓[/] [dim]{preview}[/]")
self.history.append({
"role": "tool",
"tool_call_id": tc.id,
"content": result,
})
# 安全阀:防止无限循环
if tool_count > 20:
self.console.print("[red]⚠️ Tool call limit reached (20)[/]")
break
def run(self):
self.console.print(Panel(
"[bold cyan]🪄 MagicCode[/] — 你的终端 AI 编程助手\n\n"
" [green]工具[/]: 读写文件 | 执行命令 | 搜索代码 | 编辑文件\n"
" [green]命令[/]: exit 退出 | clear 清空历史",
border_style="cyan", padding=(1, 2),
))
self.console.print(f" [dim]📂 {os.getcwd()}[/]")
self.console.print(f" [dim]🧠 {MODEL}[/]\n")
while True:
try:
user_input = self.console.input("[bold green]✦ You >[/] ")
cmd = user_input.strip().lower()
if cmd in ("exit", "quit"): break
elif cmd == "clear":
self.history = [{"role": "system", "content": SYSTEM_PROMPT}]
self.console.print("[dim]🗑️ History cleared[/]")
continue
elif not cmd: continue
self.chat(user_input)
self.console.print()
except KeyboardInterrupt:
self.console.print("\n[cyan]👋 Goodbye![/]")
break
if __name__ == "__main__":
MagicCode().run()
保存为 magic.py 然后运行:
python magic.py
试着让它创建一个文件、读回来、修改它、或运行一个命令。观察 Agentic Loop 的运作——AI 会自主串联多个工具调用来完成你的请求。
我们的 6 个工具与 Claude Code 的对比
你可能会问:6 个工具够用吗?让我们和 Claude Code 比较一下:
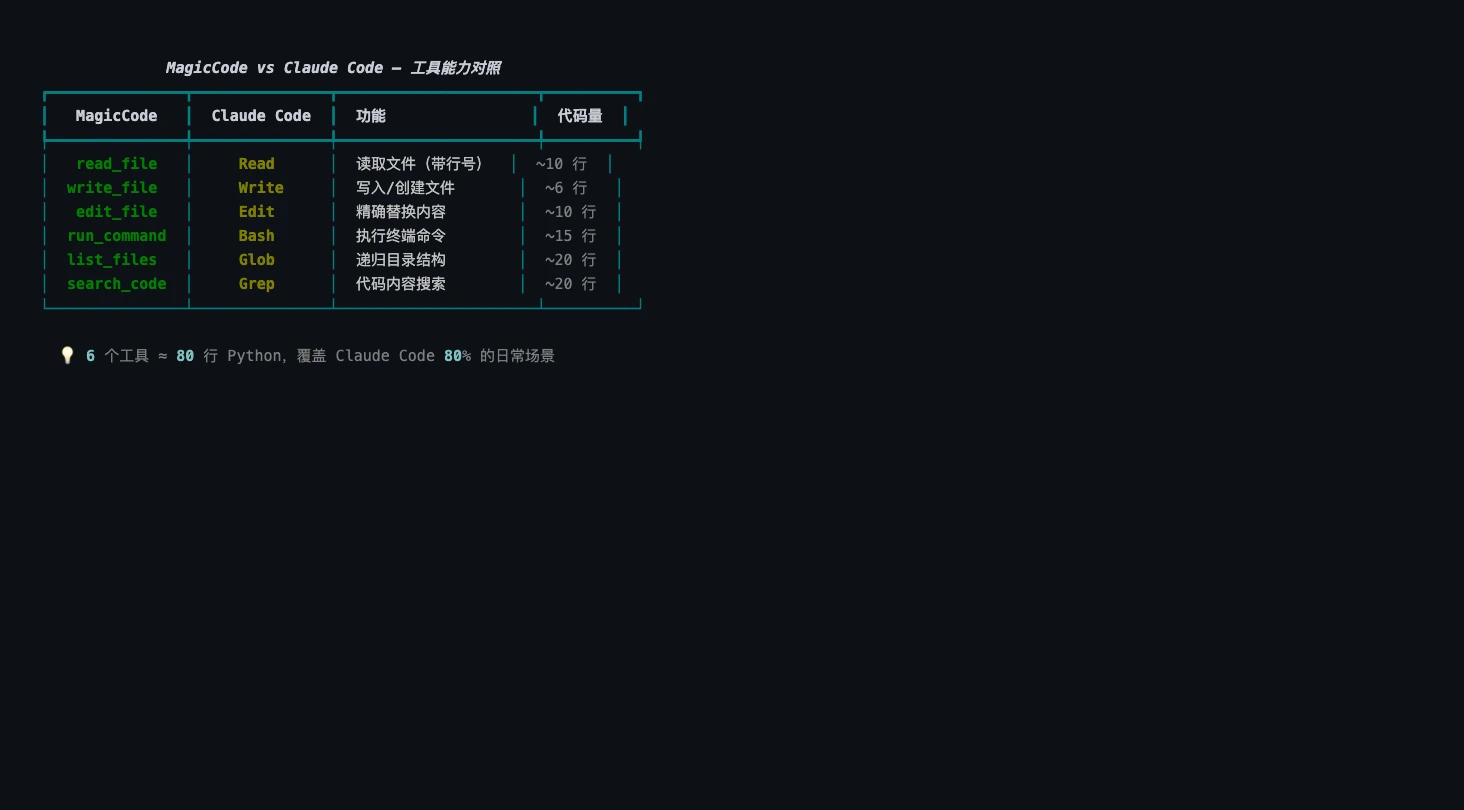
Claude Code 大约有 15 个内置工具。我们的 6 个工具覆盖了大约 80% 的日常使用场景。剩下的 20% 主要是高级功能,如 MCP 集成、多文件 diff 和笔记本编辑——锦上添花,但并非核心体验。如果你对 MCP 集成感兴趣,可以看看 MCP Server 开发教程。
五个进阶方向
基础已经打好。以下五个扩展能让 MagicCode 更接近产品级工具:
1. 权限确认
Claude Code 在写文件或执行命令前会请求确认(关于 Claude Code 安全模型的更多内容,参见 Claude Code 安全深度解析)。实现起来很简单:
def execute_tool_with_confirm(name, params):
# 只读操作:直接执行
if name in ("read_file", "list_files", "search_code"):
return execute_tool(name, params)
# 写操作:需要用户批准
console.print(f"[yellow]⚠️ {name}({params})[/]")
confirm = console.input("[bold]允许吗?(y/n) [/]")
if confirm.lower() == "y":
return execute_tool(name, params)
return "User denied this operation"
2. 项目上下文加载(CLAUDE.md)
Claude Code 会自动读取项目根目录的 CLAUDE.md 来了解上下文。我们也可以这样做:
def load_project_context():
"""加载项目配置文件作为上下文。"""
context = ""
for name in ["CLAUDE.md", "AGENTS.md", "README.md"]:
if os.path.exists(name):
with open(name, "r") as f:
context += f"\n\n--- {name} ---\n{f.read()}"
return context
# 将项目上下文追加到系统提示
project_ctx = load_project_context()
if project_ctx:
SYSTEM_PROMPT += f"\n\n## Project Context\n{project_ctx}"
3. 对话持久化
目前退出后对话历史就消失了。将它持久化到 JSON 文件:
import json
HISTORY_FILE = ".magiccode_history.json"
def save_history(history):
with open(HISTORY_FILE, "w") as f:
json.dump(history, f, ensure_ascii=False, default=str)
def load_history():
if os.path.exists(HISTORY_FILE):
with open(HISTORY_FILE, "r") as f:
return json.load(f)
return []
4. 模型切换
MagicCode 不绑定 GPT。任何支持 Function Calling 的模型都能用。OpenAI SDK 的兼容接口让切换变得轻而易举:
from openai import OpenAI
# DeepSeek
client = OpenAI(api_key="your-key", base_url="https://api.deepseek.com/v1")
# 通义千问
client = OpenAI(api_key="your-key", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
# 本地 Ollama
client = OpenAI(api_key="ollama", base_url="http://localhost:11434/v1")
这也是我们选择 OpenAI SDK 的原因之一——它是事实上的标准接口,几乎所有模型提供商都提供兼容端点。
5. Token 用量追踪
API 调用是要花钱的。添加用量追踪既简单又实用:
total_input_tokens = 0
total_output_tokens = 0
# 每次 API 调用后:
total_input_tokens += response.usage.prompt_tokens
total_output_tokens += response.usage.completion_tokens
# 退出时:
console.print(f"[dim]本次会话 token — 输入: {total_input_tokens} | 输出: {total_output_tokens}[/]")
我们构建了什么——以及它教会了我们什么
从一个 20 行的聊天机器人出发,我们逐步构建了一个功能完备的终端 AI 编程助手:
| 版本 | 能力 | 行数 | 核心技术 |
|---|---|---|---|
| V1 | 基础聊天 | 20 | Chat Completions API |
| V2 | 流式输出 | 30 | Streaming |
| V3 | 精美终端 UI | 35 | Rich + Markdown 渲染 |
| V4 | 工具系统 + Agentic Loop | 250 | Function Calling + 自主循环 |
整个架构归结为三样东西:一个 LLM API、工具定义和一个 Agentic Loop。就这些。掌握这三个概念,你就理解了 Claude Code、Cursor Agent、Copilot Workspace 以及市面上所有其他 AI 编程工具的核心架构。
完整代码就在这篇文章里——复制、粘贴、运行。如果你在此基础上构建了有趣的东西,欢迎在评论区分享。
理解你所使用的工具是如何构建的,这就是用户和工程师的区别。不要只是使用 Claude Code——理解它,然后构建更好的东西。
延伸阅读
- Claude Code 完全指南 — 深入了解如何高效使用 Claude Code
- CLAUDE.md 记忆指南:让 AI 记住你的项目 — AI 编程助手如何理解项目上下文
- 上下文工程:最被低估的 AI 技能 — 系统提示设计与上下文管理
- MCP 协议:AI 集成的通用标准 — AI 工具可扩展性的未来
- 2026 Agentic Coding 趋势报告 — Agentic Loop 如何重塑软件开发
- Claude Code Hooks 自动化指南 — 用自定义自动化扩展 Claude Code
- Vibe Coding 完全指南 — 自然语言驱动的 AI 编程方法论
Comments
Join the discussion — requires a GitHub account