OpenClaw 作者的 Claude Code 开发方法论:一个人如何用 AI 写出 10 万星项目
深度拆解 OpenClaw 作者 Peter Steinberger 的 Claude Code 开发方法论,从 AGENTS.md 文档驱动、多 Agent 并行开发到 Spec 驱动构建,手把手教你用同样的方法让 Claude Code 帮你做项目。
Claude CodeOpenClawAI 编程Agent EngineeringAGENTS.md
1394 Words
2026-01-31 14:50 +0000
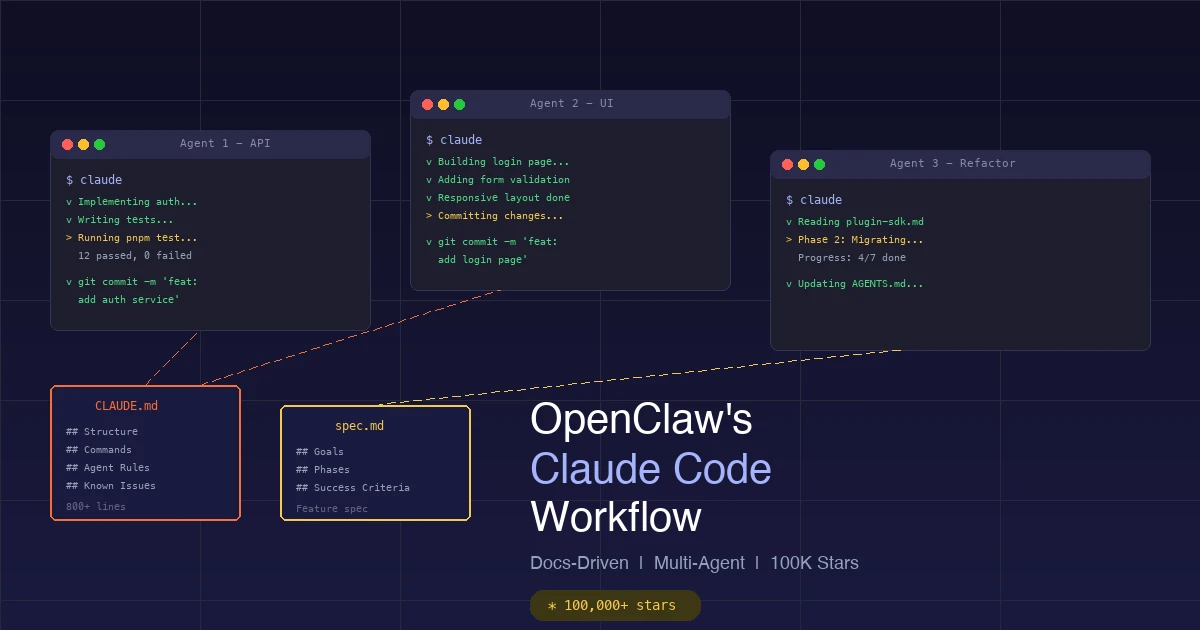
最近有个项目彻底火了——OpenClaw(前身 Clawdbot),一个开源 AI 助手,72 小时拿下 6 万 GitHub stars,一周吸引 200 万访客,现在已经突破 10 万星。
最让人震惊的不是它有多火,而是它背后只有一个人——奥地利开发者 Peter Steinberger(@steipete)。他没有团队,没有 996,全靠 Claude Code 和 Codex CLI 同时开 5-10 个 Agent 并行开发,日均提交 600+ 次 commit。
从提交记录来看,你会以为这是一家公司在做:
“From the commits, it might appear like it’s a company. But it’s not. This is one dude sitting at home having fun.”
这篇文章会完整拆解他的开发方法论,让你读完就能用同样的方式让 Claude Code 帮你做项目。
一、背景:一个退休开发者如何重新出山
Peter Steinberger 是 PSPDFKit(后以 1.19 亿美元出售)的创始人。2021 年退休后,他消失了三年。2025 年 4 月,他重新开始写代码,但这次,他的"手"变了——不再亲手敲键盘,而是让 AI 来干。
他的第一次尝试是这样的:
- 把一个 1.3MB 的 Markdown 文件拖进 Gemini,说:“Write a specification”
- Gemini 输出了 400 行规范文档
- 把规范文档拖进 Claude Code,说:“Build”
- 不停点 “continue”
程序崩溃了。但他看到了潜力。
从那以后,他花了 8 个月时间打磨出一套完整的 AI 开发方法论,从"Claude Code 是我的电脑"到"我发布自己不读的代码",最终造出了 10 万星的 OpenClaw。
二、核心理念:Agent Engineering,不是 Vibe Coding
Peter 明确拒绝"Vibe Coding"(氛围编程)这个说法。他更倾向于叫它 Agent Engineering(代理工程):
- 人类负责:系统架构、产品设计、技术选型、质量把控
- AI 负责:代码实现、调试、测试、重构
这不是"随便让 AI 写写看",而是一套有纪律的工程方法。他对此的总结是:
“Using AI simply means that expectations what to ship went up."(使用 AI 只是意味着对交付物的期望提高了。)
三、文档驱动开发——OpenClaw 的核心秘密
打开 OpenClaw 的 GitHub 仓库,你会发现根目录有两个关键文件:
AGENTS.md——800+ 行的 AI Agent 指导手册CLAUDE.md——指向AGENTS.md的符号链接
这两个文件是整个项目的"大脑”。每次 Claude Code 或 Codex 启动时,都会读取这个文件,就像给新入职员工发的《工作手册》。
3.1 AGENTS.md 里写了什么?
Peter 把 AGENTS.md 描述为:
“a collection of organizational scar tissue”(一份组织伤疤的集合)
意思是——每次踩坑后,他都让 AI 在这个文件里记一笔,防止同样的错误再犯。这个文件不是他自己写的,而是 AI 自己写、自己维护的。
AGENTS.md 的核心内容包括 7 大模块:
模块一:项目结构
- Source code: src/ (CLI in src/cli, commands in src/commands)
- Tests: colocated *.test.ts(测试文件和源码放一起)
- Docs: docs/(文档目录)
- Plugins: extensions/*(插件目录)
告诉 Agent 代码在哪、测试在哪、文档在哪——不需要每次都问。
模块二:构建/测试命令
pnpm install # 安装依赖
pnpm build # 构建
pnpm test # 跑测试 (vitest)
pnpm lint # 代码检查 (oxlint)
pnpm format # 格式化 (oxfmt)
pnpm test:coverage # 覆盖率测试
为什么这很重要?因为 AI 代理必须能自我验证——能编译、能测试、能检查自己的输出。这是 Peter 反复强调的核心原则:
“The key is that the AI can verify its own work. It must be able to compile, lint, execute, and verify the output.”
模块三:编码风格
- Language: TypeScript (ESM). Prefer strict typing; avoid any.
- Keep files concise; extract helpers instead of "V2" copies
- Aim to keep files under ~700 LOC
- Naming: OpenClaw for product/docs; openclaw for CLI/package/paths
模块四:Git 提交规范
# 使用自定义脚本提交,避免手动 git add/commit
scripts/committer "<msg>" <file...>
这个自定义脚本确保每次提交只包含指定文件,不会误提交其他 Agent 修改的内容。
模块五:多 Agent 安全规则(最关键的部分)
- do NOT create/apply/drop git stash unless explicitly requested
- Assume other agents may be working; keep unrelated WIP untouched
- when the user says "commit", scope to your changes only
- do NOT switch branches unless explicitly requested
- when you see unrecognized changes, keep going; focus your changes
这段规则解决了一个关键问题:多个 AI Agent 同时在同一个代码库工作时,如何避免互相踩踏? 答案是——每个 Agent 只管自己的事,看到不认识的改动不要碰。
模块六:文档规范
- Internal doc links: root-relative, no .md/.mdx
- Doc headings: avoid em dashes and apostrophes
- Docs content must be generic: no personal device names/hostnames
模块七:特殊规则
- Vocabulary: "makeup" = "mac app"(Peter 的个人黑话)
- Never edit node_modules
- Never update the Carbon dependency
- Bug investigations: read source code of npm deps AND local code
3.2 docs/ 目录:给 AI 看的需求文档
OpenClaw 的 docs/ 目录下有 30+ 个子目录,其中最关键的是:
docs/concepts/(30 个概念文档)
| 文件 | 内容 |
|---|---|
architecture.md | 系统架构(WebSocket 控制平面) |
agent.md | 代理运行时 |
agent-loop.md | 代理执行循环 |
multi-agent.md | 多代理路由 |
system-prompt.md | 系统提示组装 |
memory.md | 记忆管理 |
session.md | 会话管理 |
streaming.md | 数据流 |
context.md | 上下文管理 |
这些文档的作用是——当 Agent 需要修改某个子系统时,它可以先读对应的概念文档,理解系统设计意图后再动手。
docs/refactor/(重构规划文档)
这是最有启发性的部分。Peter 不是直接让 AI 重构代码,而是先写好重构计划书,然后让 AI 按计划执行。
以 plugin-sdk.md 为例,它包含:
## 目标
Every messaging connector is a plugin (bundled or external) using one stable API
## 非目标
不在此次重构范围内的内容
## 实施阶段
- Phase 0: 准备工作
- Phase 1: 定义 Plugin SDK 接口
- Phase 2: 迁移第一个内置通道
- Phase 3: 迁移所有内置通道
- Phase 4: 外部插件支持
- Phase 5: 清理和文档
## 成功标准
- 所有内置通道迁移为插件
- 外部插件能使用相同 API
- 测试覆盖率 > 70%
这种文档结构让 AI Agent 清楚知道:做什么、不做什么、分几步做、什么算完成。
3.3 Bootstrap 文件系统:AI 的"入职培训包"
OpenClaw 还有一套"人格注入"系统,每个新 AI 会话启动时自动加载:
| 文件 | 用途 |
|---|---|
AGENTS.md | 操作指令和记忆 |
SOUL.md | 人格、边界、语气 |
TOOLS.md | 工具使用笔记 |
IDENTITY.md | 代理名称/风格 |
USER.md | 用户个人资料 |
BOOTSTRAP.md | 首次运行仪式 |
这套系统确保每次新会话的 AI 都"知道自己是谁、用户是谁、项目是什么"。
四、Spec 驱动构建——从需求到代码的完整流程
这是 Peter 最核心的工作流,也是你最容易复制的部分。完整流程分 6 步:
第 1 步:收集需求素材
用 repo2txt 把参考项目的 GitHub 仓库转成 Markdown 文本,或者手动收集需求文档、API 文档、竞品分析等。
第 2 步:用 Gemini 生成规范
把素材拖入 Google AI Studio(Gemini 有超大上下文窗口),让它生成软件设计文档(SDD),大约 500 行。
第 3 步:反复审查规范
在新的 Gemini 会话中,对 SDD 进行"拆解审查":
“Take this SDD apart. Give me 20 points that are underspecified, weird, or inconsistent.”
把审查意见反馈回原始文档,迭代 3-5 轮,直到规范足够清晰。
第 4 步:保存为 spec.md
把最终规范保存到项目的 docs/spec.md。
第 5 步:让 Claude Code 执行
打开 Claude Code,输入一句话:
Build spec.md
不需要复杂的提示词,因为规范文档已经包含了一切:目标、约束、API 设计、数据模型、分阶段计划。
第 6 步:AI 自主实现
Claude Code 会在 2-4 小时内完成实现,期间只需要你偶尔确认方向,大部分时间都是 AI 自主工作。
“Claude Code doesn’t need complex prompting because the spec contains everything it needs, eliminating ambiguity.”
五、多 Agent 并行开发——一个人的"团队"
这是 Peter 最疯狂也最高效的实践:同时运行 5-10 个 AI Agent,在 3×3 终端网格中并行工作。
5.1 硬件设置
| 设备 | 用途 |
|---|---|
| Dell 40" 曲面屏 (3840×1620) | 主屏,同时显示 4 个 Claude + Chrome |
| Ghostty 终端 | 替代 VS Code 终端(更稳定) |
| WisprFlow | 语音转文字输入 |
5.2 并行策略
Agent 数量根据工作类型动态调整:
| 工作类型 | Agent 数量 | 原因 |
|---|---|---|
| 重构 | 1-2 个 | 影响范围大,需要串行 |
| 测试/清理 | ~4 个 | 互不干扰 |
| UI + 后端 + 文档 | 5-8 个 | 不同模块并行 |
5.3 协作规则
所有 Agent 在同一个文件夹、同一个 main 分支工作,不用 worktree,不用分支。靠 AGENTS.md 里的规则保持秩序:
- 每个 Agent 只提交自己修改的文件
- 使用
scripts/committer脚本做原子提交 - 看到不认识的改动,忽略它,专注自己的任务
- 拉取代码时用
git pull --rebase,不丢弃其他 Agent 的工作
5.4 为什么不用分支?
Peter 的理由很直接:
“Once you parallelize, execution time of one agent does not matter that much anymore.”
分支意味着合并冲突。在 main 上直接工作,每个 Agent 做原子提交,冲突反而更少。
六、CLI 优于 MCP——Peter 的反直觉选择
很多人用 Claude Code 时会装一堆 MCP Server(GitHub MCP、文件系统 MCP 等)。Peter 的做法恰好相反——他不用任何 MCP:
“I don’t use any MCPs… keeping your context as clean as possible is important. If you add MCPs, you just bloat the context.”
他的核心论点:
| 方式 | Context 开销 |
|---|---|
| GitHub MCP | 23,000 tokens |
gh CLI | 0 tokens(模型原生会用) |
怎么让 Claude Code 用 CLI 工具?只需要在 CLAUDE.md 写一行:
Use `gh` CLI for all GitHub operations.
模型会自己尝试,失败了会看帮助文档,然后学会怎么用。
“The beauty is all you need is like one line in your CLAUDE file… And then the model will eventually try some random shit. It will fail. It will print the help message… And then the model knows how to use the CLI.”
Peter 推荐的 CLI 工具:
gh— GitHub 操作vercel— 部署psql— 数据库axiom— 日志查询- 自建 CLI:
bslog(日志)、xl(Twitter API)
七、实操指南:照搬 Peter 的方法做你的项目
说了这么多理论,现在是实操环节。以下是你可以立即复制的步骤:
第 1 步:创建 CLAUDE.md
在你的项目根目录创建 CLAUDE.md,写入以下内容(根据你的项目调整):
# CLAUDE.md
## 项目概述
[一段话描述项目是什么、解决什么问题]
## 技术栈
- 语言:TypeScript
- 框架:Next.js
- 数据库:PostgreSQL
- 测试:vitest
## 项目结构
```
src/
├── app/ # 页面路由
├── components/ # UI 组件
├── lib/ # 工具函数
├── services/ # 业务逻辑
└── types/ # 类型定义
```
## 常用命令
```bash
pnpm dev # 启动开发服务器
pnpm build # 构建
pnpm test # 跑测试
pnpm lint # 代码检查
```
## 编码规范
- 使用 TypeScript strict 模式
- 文件保持在 500 行以内
- 测试文件与源码放在一起
## Git 规范
- 原子提交:每次只提交一个功能的改动
- 提交信息使用英文,格式:`type: description`
- 不要动 node_modules 和 .env 文件
## 已知问题
[AI 踩过的坑记在这里,防止重复]
第 2 步:写 Spec 文档
在 docs/ 目录下创建功能规范文档。模板:
# Feature: [功能名称]
## 目标
[这个功能要实现什么]
## 非目标
[明确不在这次实现范围内的内容]
## 设计方案
### 数据模型
[数据库表结构或接口定义]
### API 设计
[接口路径、请求/响应格式]
### UI 设计
[页面结构、交互流程]
## 实施计划
- Phase 1: [基础框架]
- Phase 2: [核心逻辑]
- Phase 3: [UI 完善]
- Phase 4: [测试和优化]
## 成功标准
- [ ] [具体的验收条件]
- [ ] [测试覆盖率要求]
第 3 步:让 Claude Code 执行
# 启动 Claude Code
claude
# 告诉它执行 spec
> Read docs/spec.md and implement Phase 1.
每完成一个阶段,再给下一个:
> Phase 1 is done. Now implement Phase 2.
第 4 步:让 AI 维护 CLAUDE.md
遇到问题时,不要自己改 CLAUDE.md,让 AI 来:
> We just hit a bug where the API returns 500 when the request body is empty.
> Add a note about this in CLAUDE.md so we don't make the same mistake again.
随着项目推进,CLAUDE.md 会自然积累越来越多的"组织记忆"。
第 5 步:尝试多 Agent 并行
如果你有一个中大型项目,可以同时开多个终端窗口:
# 终端 1:实现后端 API
claude
> Implement the user authentication API based on docs/auth-spec.md
# 终端 2:实现前端页面
claude
> Build the login page UI based on docs/auth-spec.md
# 终端 3:写测试
claude
> Write comprehensive tests for src/services/auth.ts
注意:在 CLAUDE.md 中加上多 Agent 安全规则:
## 多 Agent 规则
- 只提交你自己修改的文件
- 看到不认识的改动不要碰
- 不要 git stash 或切换分支
八、Peter 的反直觉经验
最后,分享几个 Peter 在实践中总结的反直觉经验:
“不读代码也能发布”
“These days, I don’t read much code anymore. I watch the stream and sometimes look at key parts.”
他不逐行审查代码,而是关注架构和组件关系。让 AI 写测试来验证正确性,而不是靠人肉 Review。
“20% 时间专门用于重构”
AI 生成的代码初始比较松散,需要定期整理:
- 用
jscpd查代码重复 - 用
knip查死代码 - 拆分超过 700 行的大文件
- 更新依赖版本
这些清理工作全部交给 AI Agent 做,人只需要发出指令。
“截图比文字描述更高效”
“A screenshot takes 2 seconds to drag into the terminal.”
Peter 约 50% 的提示包含截图。特别是 UI 开发时,截图一张效果比写三段描述更好。
“别浪费时间在花哨的工具上”
“Don’t waste your time on stuff like RAG, subagents, Agents 2.0 or other things that are mostly just charade. Just talk to it. Play with it. Develop intuition.”
不需要 RAG,不需要复杂的多 Agent 框架,就用最简单的方式——跟 AI 对话,给它足够的上下文(CLAUDE.md + spec),让它干活。
“AI 反而逼出了更好的架构”
因为 AI 需要能自我验证,所以系统必须模块化、可测试。这反过来让代码质量比以前更高。
总结
Peter Steinberger 用 Claude Code 开发 OpenClaw 的方法论,核心就三个字:写文档。
| 层次 | 文档 | 作用 |
|---|---|---|
| 项目级 | CLAUDE.md / AGENTS.md | Agent 的"工作手册",持续积累项目记忆 |
| 功能级 | docs/spec.md | 给 Agent 的任务书,写清目标和分阶段计划 |
| 子系统级 | docs/concepts/*.md | Agent 理解系统设计的参考文档 |
| 重构级 | docs/refactor/*.md | 分阶段重构计划,Agent 按步骤执行 |
工作流也很简单:
- 人类写 Spec(或用 Gemini 生成 + 审查)
- CLAUDE.md 提供上下文(项目结构、编码规范、已知问题)
- Claude Code 执行(“Build spec.md”)
- AI 自我验证(编译、测试、lint)
- 踩坑后更新 CLAUDE.md(让 AI 自己记录)
- 定期重构清理(20% 时间)
这不是什么高深的理论。它的核心逻辑就是——你不需要亲手写代码,但你需要亲手写清楚你要什么。
Spec 越清晰,AI 执行越准确。文档越完善,Agent 越少犯错。这套方法,一个人就能做出"一家公司"的产出。
参考链接:
- OpenClaw GitHub 仓库
- OpenClaw AGENTS.md
- Claude Code is My Computer - Peter Steinberger
- My Current AI Dev Workflow - Peter Steinberger
- Just Talk To It - Peter Steinberger
- Shipping at Inference-Speed - Peter Steinberger