Message Queue Fundamentals: Core Concepts, Use Cases, and Technology Selection
A comprehensive guide to message queues in distributed systems — covering the Producer-Broker-Consumer model, key benefits (decoupling, async processing, load leveling), trade-offs, and how to choose between RabbitMQ, Kafka, RocketMQ, and ActiveMQ.
858 Words
2019-07-31
A message queue is a middleware component that stores messages in transit between producers and consumers. Its primary purpose is to provide reliable message delivery — if the receiver is unavailable when a message is sent, the queue holds it until delivery succeeds.
What Is a Message Queue?
At its simplest, a message queue follows the Producer-Broker-Consumer model:
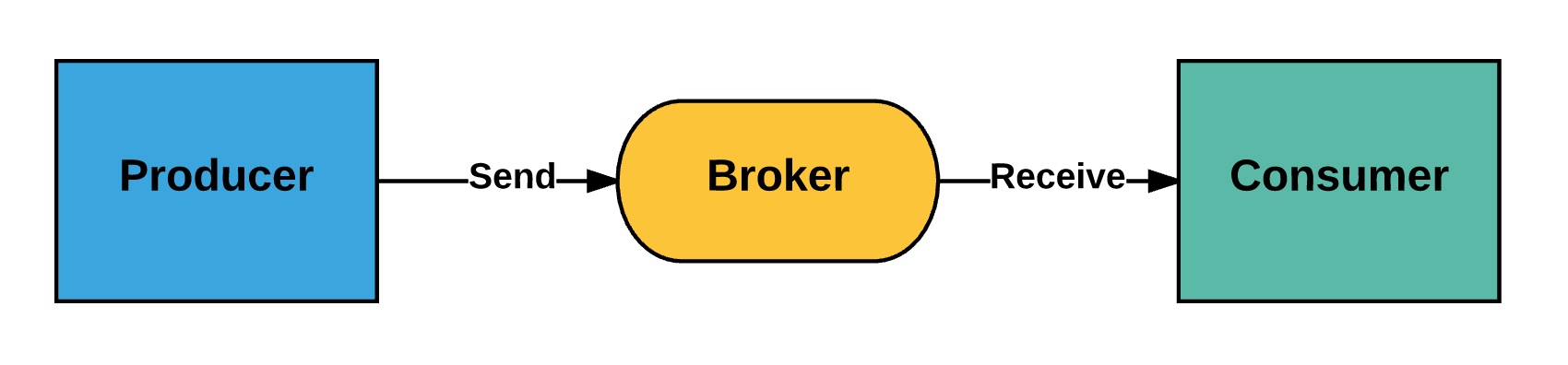
- Producer: Creates and sends messages to the broker
- Broker: Stores, acknowledges, and retries messages; typically manages multiple queues
- Consumer: Retrieves messages from the broker and processes them
Message queues are a critical component of distributed systems, primarily used to improve performance through async processing, smooth out traffic spikes, and reduce coupling between services.
A Practical Example
Imagine a developer is asked to implement “send a confirmation email after a user places an order.” The quick solution: call the email-sending code right after the order is placed, synchronously. It works — until monitoring shows that order processing is too slow because the email step blocks the response.
The developer moves email sending to a separate thread. It’s faster, but now emails are occasionally lost when the thread crashes.
The solution: publish a message to a queue after the order is placed. The email service subscribes to that queue and processes messages independently. The order service doesn’t need to know where the email service is or how it works — it just publishes the message and moves on.
As more teams adopt this pattern and message volume grows, multiple consumers are added to process the queue in parallel. This is distributed message processing in action.
Why Use a Message Queue?
When producers and consumers operate at different speeds or have different reliability characteristics, a message queue bridges the gap. The three core benefits are: decoupling, async processing, and load leveling.
1. Decoupling
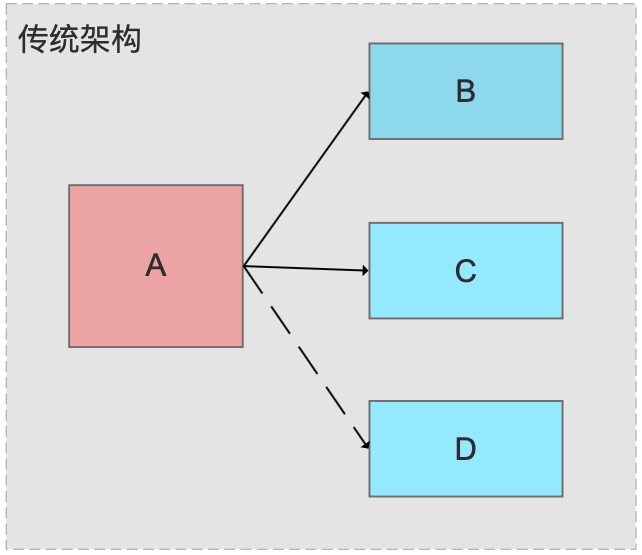
Scenario: System A updates data and needs to notify systems B and C. System D will join later.
Without MQ: A calls B and C directly via API. Problems: (1) tight coupling, (2) if B or C is down, the update fails, (3) adding D requires changes to A.
With MQ: A publishes to the queue. B, C, and D each subscribe independently. A doesn’t need to change when new consumers are added.
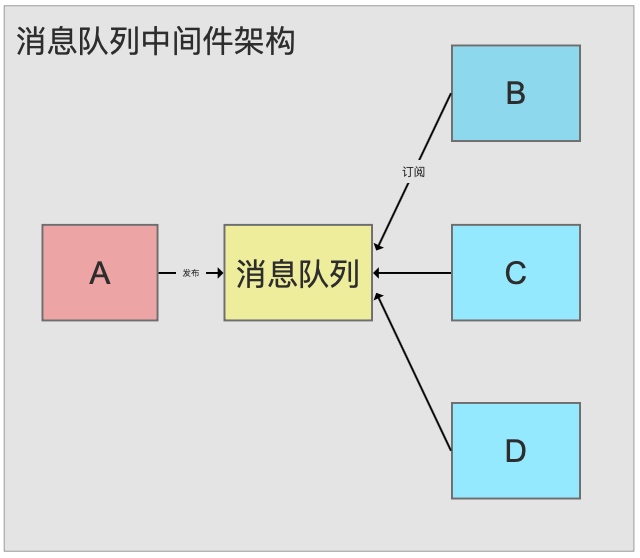
Producers and consumers don’t need to know about each other at all.
2. Async Processing
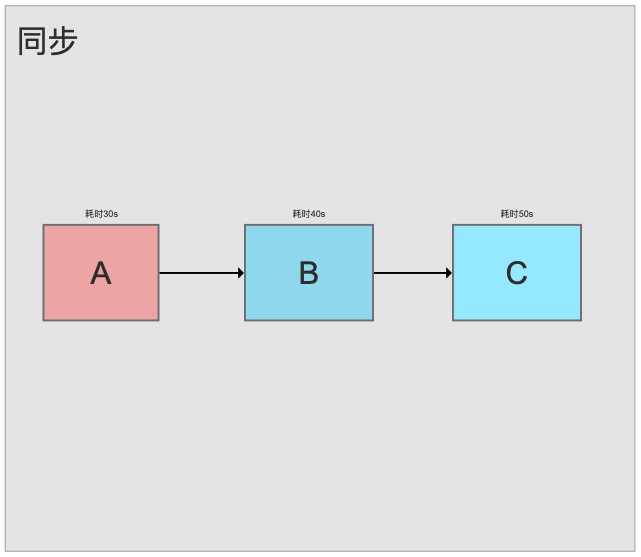
In synchronous mode, the total processing time is 120 seconds.
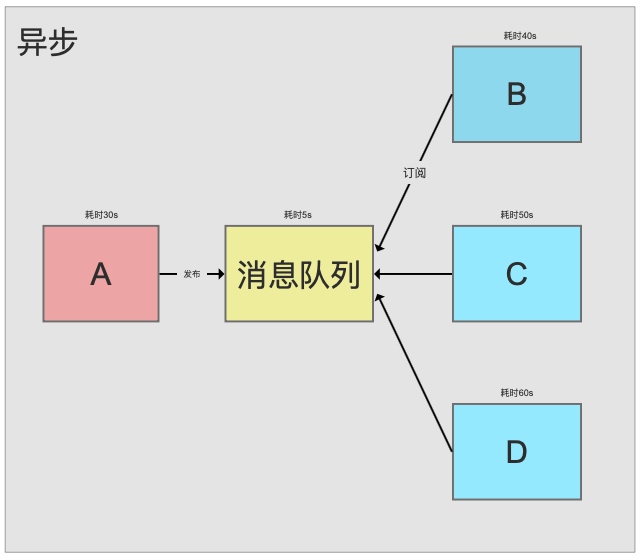
With async processing via MQ, the response takes only 35 seconds. Non-critical workflows (B, C) run asynchronously, dramatically improving response times.
3. Load Leveling (Peak Shaving)
Scenario 1: System A has 10,000 data updates to send to B and C.
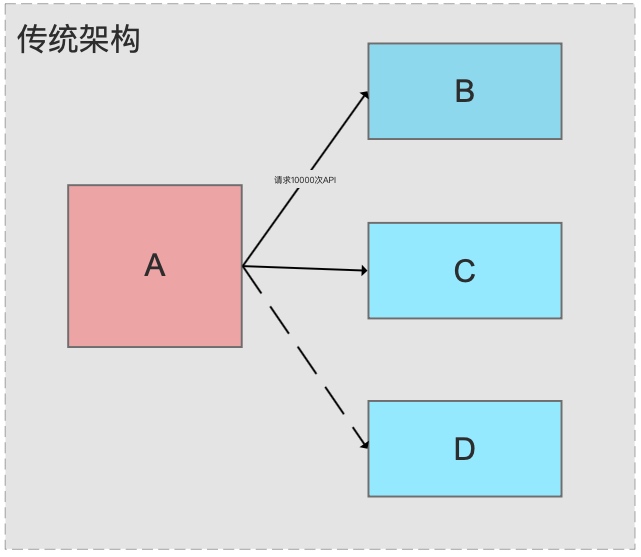
Without MQ, A pushes directly to B and C. If the volume exceeds their processing capacity, they crash.
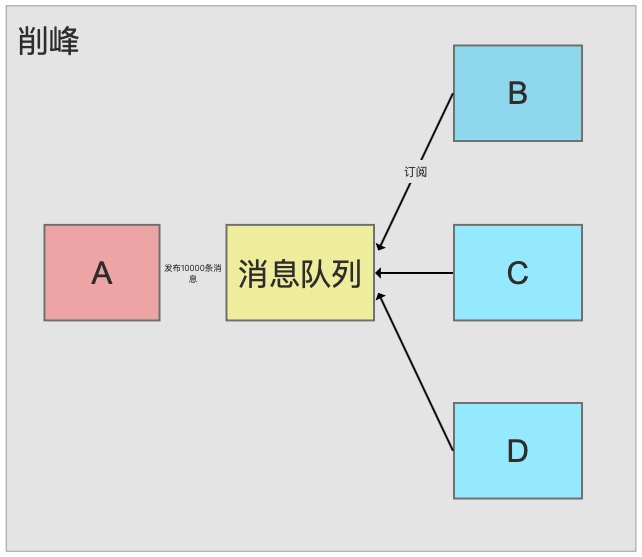
With MQ, B, C, and D consume at their own pace. Brief message accumulation during traffic spikes is acceptable.
Scenario 2: A system handles 50 requests/second most of the day, but during the lunch hour, traffic spikes to 5,000+ requests/second. The MySQL backend can handle 2,000/second max. Without MQ, the database crashes during the spike. With MQ, all requests are written to the queue first, and the system processes them at a sustainable rate (2,000/second). The backlog clears quickly once the peak passes.
Trade-offs of Using a Message Queue
1. Reduced System Availability
Adding MQ introduces a new point of failure. You now need to handle scenarios like MQ downtime and message loss.
2. Increased System Complexity
Direct API calls are simple. MQ adds message delivery guarantees, duplicate consumption prevention, data consistency challenges, and longer message delivery chains with higher latency.
When to Use a Message Queue
1. Data-Driven Task Dependencies
Some tasks must run in sequence — for example, syncing orders before updating inventory before generating pick lists.
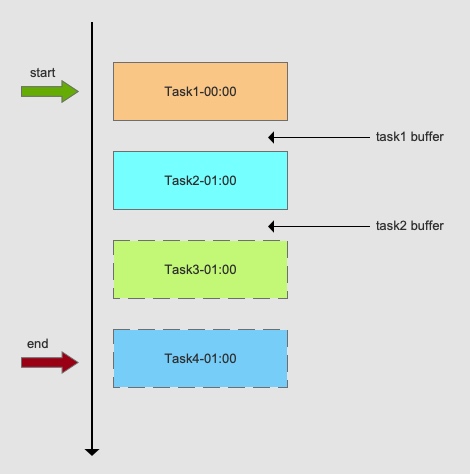
The traditional approach uses cron jobs with estimated buffer times between tasks. This breaks when a task takes longer than expected, wastes time on buffers, and doesn’t scale well when dependencies change.
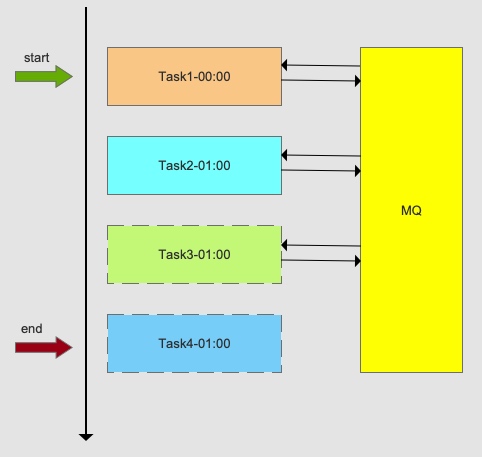
With MQ, each task publishes a completion message when it finishes. Downstream tasks subscribe to these messages and start immediately — no buffers needed, no manual coordination required. Note: MQ only carries completion signals, not the actual data.
2. Fire-and-Forget Workflows
When the upstream service doesn’t need to know if the downstream task succeeds. For example, after placing an order, publish a message to trigger the confirmation email. The order service doesn’t care whether the email actually sends.
3. Long-Running Async Operations
When a task takes a long time to complete and the caller needs the result eventually. For example, in a payment flow: the client initiates payment, the payment service processes it asynchronously, and publishes the result to MQ. The client subscribes and receives the outcome as soon as it’s available.
How to Choose a Message Queue
Here is a comparison of the most widely-used message queues:
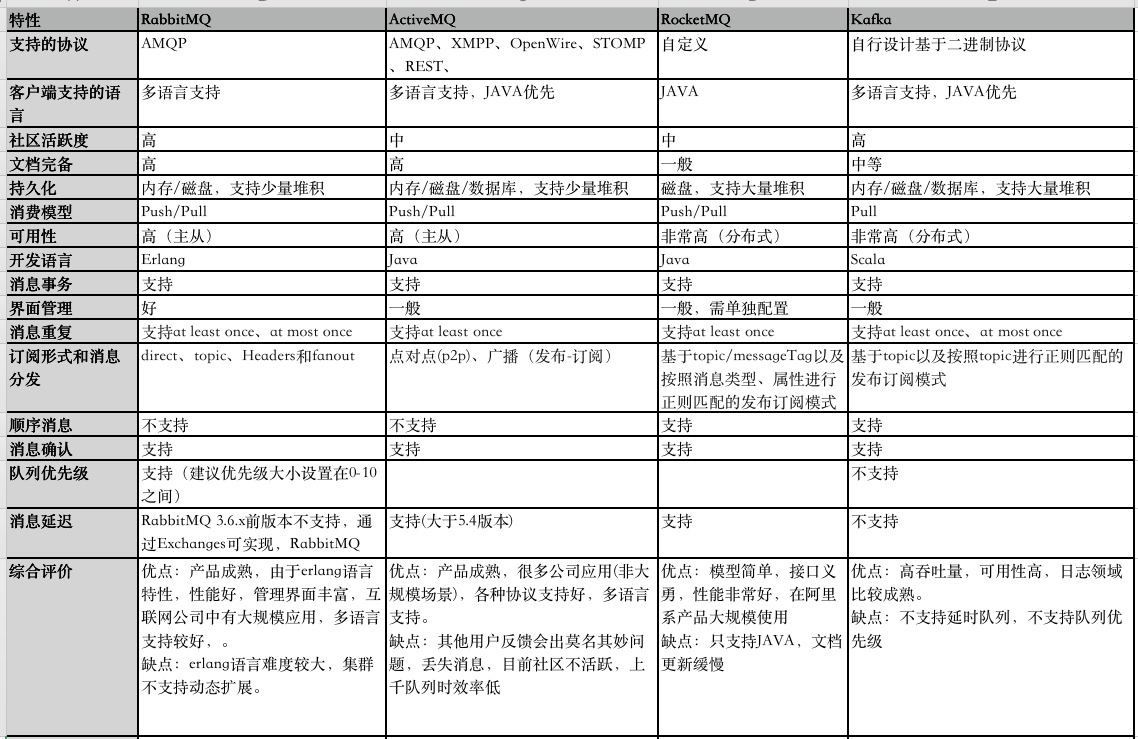
Technology selection must be driven by actual business needs. For small-to-medium companies, RabbitMQ is a solid choice — it’s easy to manage, has an active community, extensive documentation, and broad language support. Kafka is better suited for big data pipelines and high-throughput streaming scenarios.
Comments
Join the discussion — requires a GitHub account